

-
Tweets472
-
Followers245
-
Following958
-
Likes3K

Most researchers agree that autoregression is best when memory bandwidth is cheap and diffusion is best when FLOPS are cheap. They also admit the future of compute is all FLOPS because memory scaling is hard and scaling FLOPS is easy. So why not go all in on diffusion????

the sloptimizer field is just getting started with shampoo and muon gen algorithms, the graveyard of adam variants got so bad you can't list them all on a page


Moratorium on new optimizers until we figure out whats going on
@srush_nlp It's nice that everything has a clean referent but bad that it's all informationally flat. They should be named as honestly as the wandb runs: GRPO-tweak1 GRPO-tweak2 GRPO-tweak2+tweak1
Low exploration costs improve craftsmanship. I can think of few trades where free, low-cost exploration doesn't lead to better knowledge and craftsmanship. Software design has been largely, rightly, guided by risk-aversion. A changing explore/exploit balance is a good thing.
Slop generators like Ralph, Loom and Gastown treat developers as if they are free resources, replacing costly humans with swarms of agents churning out specs or cloned patterns. My take is that the real disruption is not about free labor, but about the fact that changing your
Even simpler: it's just a basic requirement because there isn't enough time or $ to gridsearch your idea. And if gridsearching your idea is the only way to make it work it's probably not worth it anyway.

ablations are for the weak. just yolo your runs. (ok, do some small amount of ablations, but don't over do it). instinct is everything in ML and AI.
@jxmnop why do you think models won't close the gap on writing good kernels?
@LysandreJik Agree with the sentiment - those all seemed like big, distant step changes in the early decoder days. And very cool viz. That said...the dates are broken for all those models.

Getting to the heart of the matter here, and fixing it. Heard many times batching is the culprit, but this is the first in-depth explanation I've seen.


Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference” We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to

It's one thing to read about reward hacking in the literature and think it's not that bad, it's another thing to do some RL and see that reward hacking really got hands
@zmkzmkz haha ok that makes sense. Either way, as the model size scales up the cost of that extra unembedding gets amortized away. Good to know for the smaller model comparisons though.
@zmkzmkz Nice, TOP uses fewer flops per step? I was thinking about the extra unembedding in TOP - do you cut out a layer somewhere to compensate?
@robinhanson An Atlantic article with some summaries and links out to the research. Interesting article, I don't see this specific interpretation in there though. archive.is/ha0nL
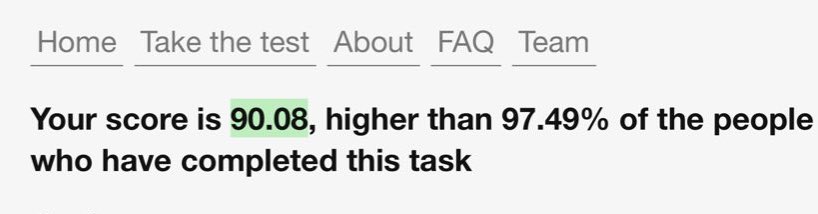
> score is calculated based on "how often words are used together" > just pick obscure words that don't get used at all > rejected
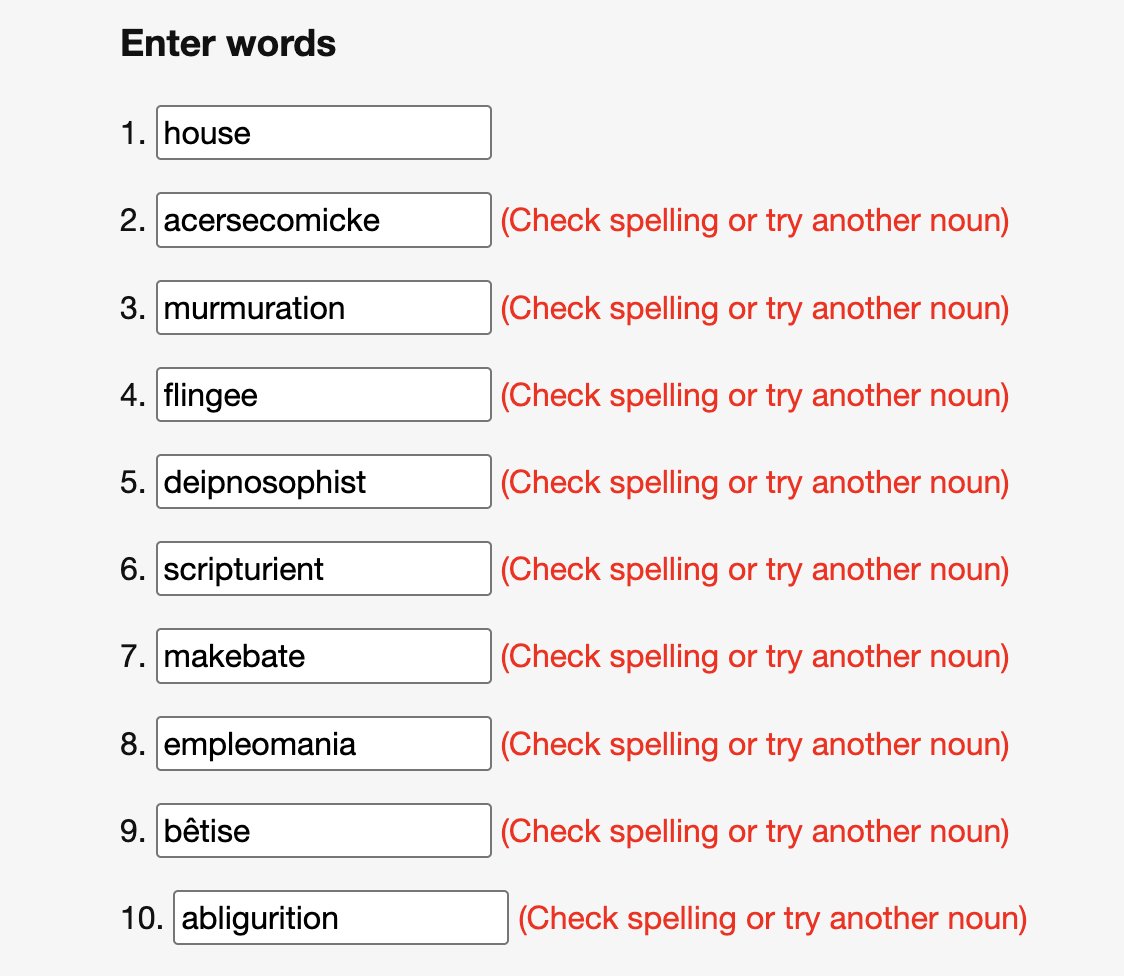

what’s the highest you guys got to on the divergent vocabulary test
@xeophon Nice eval! Interesting framing though. Would you interpret the task as measuring a behavior, without opining on whether this behavior is good or bad? Or is it just good? I'd say there are clear use cases where this behavior is nice and where it is not nice.
TIL some people are still using ROUGE

The Illusion of Progress It's well known that there are caveats with benchmarks and metrics that measure LLM capabilities. It's no different for hallucination detection. "ROUGE fails to reliably capture true hallucination" Here are my notes:

@immortal_0698 @natolambert Sure, but if you're not forced to use it then it's just a bad feature that you don't use.
@gatelice_ @ddkang Sure, and as you say there are scenarios where a datapoint is worth $100 or $1000 or $1 or $.01. I'm trying to get the authors to provide the evidence they used for their estimates.



reece scoggins @romenotinaday
2 Followers 532 Following
Lubos @Lubos1444975
22 Followers 814 Following
Allen Schmaltz @Allen_Schmaltz
758 Followers 3K Following AI/ML @ Reexpress AI (https://t.co/z0yUIZBt1l) | Research: AI:=Introspection+Updatability+Uncertainty (Similarity⧉Distance⧈Magnitude⧇)
igloo1 @igloonocti25
14 Followers 263 Following
🧹🪣 Jennifer Mil... @7q1R5266mozjTCL
59 Followers 1K Following
Jonathan hind @import_hind
58 Followers 1K Following

Matilda @9bTMc0yM5B2LxCG
93 Followers 3K Following If you’re going to be two-faced, at least make one of them pretty.
Arfwuire @Arfwuire034
76 Followers 2K Following



Muiaulaw @Muiaulaw190166
31 Followers 1K Following Don’t wait for someone to save you. Save yourself.
DaftoPunko @dafto_punko
254 Followers 8K Following
Monica @HsCXX5OC5N3DfsJ
46 Followers 976 Following
SabrinaWells @xoQo7rhW7kHUCE6
34 Followers 986 Following Keep shining, beautiful one. The world needs your light.
AfraMorrison @Zu3v1tPVeAbDXz
145 Followers 6K Following
Alfeecag @Alfeecag619406
42 Followers 1K Following I’m not a backup plan, and definitely not your second choice.
Zara @Y6i6iW39f8gM50K
54 Followers 1K Following
Gpbhupinder @gpbhupinder
386 Followers 8K Following 🚀Generative AI | Python | Deep Learning | React, Next.js 👨💻 Full-Stack Developer & AI Integration Expert


Kashish Jagga @kashish_jagga
21 Followers 4K Following

Jim Xu @_j_xu
46 Followers 138 Following DS @nytimes // prev @meta // M.S. @BerkeleyISchool // 1st gen // occasional commentary on economics and mental health // he/they 🏳️🌈

EmpressAbigailNelson @LxLYeZP1Br6g1
15 Followers 1K Following Grateful for today, excited for tomorrow. #Goals

Yoram Bachrach @yorambac
4K Followers 7K Following Research Scientist at Meta (prev Google DeepMind and Microsoft Research). Working on LLM Agents and Multi-Agent Systems.

Saber Darabi @SADarabi
237 Followers 7K Following Cloud-Native,Independent Scientist,Nomad Researcher
Scott Schindler @scotty529
420 Followers 1K Following AI + product engineer building https://t.co/ze0EuvGKe6

Luna @Ip3RuJy642zUfrl
16 Followers 786 Following
Paul Ritchie @PaulRitchi89793
117 Followers 3K Following
FaitheEvan @tUQo3s4M4518TOy
45 Followers 1K Following
Harness Engineering @harnessengr
250K Followers 11K Following The more things change, the more they stay the same. DM for repost
Roxanne @8zs5t2GEi2aIq
14 Followers 816 Following
Luna @2Z9K4xAUt7eF4v3
26 Followers 1K Following

赵华真 @IGw7NLVynU94445
0 Followers 5 Following
再生エネルギー... @Otearso163980
36 Followers 2K Following 【完全無料】 25年の株式投資プロチーム(運用資産500億円以上)が提供:毎日の市場分析レポート + 優良成長株のピックアップ。プロの情報を無料で。まずはお気軽にお問い合わせください。
ExplorerAmeliaMartin @Gareaja4843387
27 Followers 2K Following The sky's the limit Finding joy in the little things

steve @gpusteve
2K Followers 1K Following cofounder @wafer_ai (yc s25) ⿻ prev @twosigma, @google, @seinetwork, @uchicago
Matthew Prince 🌥 @eastdakota
216K Followers 301 Following A little bit geek, wonk, and nerd. Repeat entrepreneur, recovering lawyer, and former ski instructor. Co-founder & CEO of Cloudflare (NYSE: NET).

The AI Timeline @TheAITimeline
26K Followers 1 Following covering the latest trending AI & LLM research, see "highlights" for all weekly threads, ran by @bycloudai
Bowen Peng @bloc97_
2K Followers 87 Following
Russell Kaplan @russelljkaplan
22K Followers 738 Following President @cognition. Past: director of engineering @Scale_AI, startup founder, ML scientist @Tesla Autopilot, researcher @StanfordSVL.
Rayan Krishnan @RayanKrishnan
670 Followers 326 Following ceo @ValsAI | solve evals, solve intelligence prev @stanford @PalantirTech
Yulun Du @Yulun_Du
5K Followers 889 Following Scaling @Kimi_Moonshot prev @LTIatCMU Opinions are my own.Corry Wang @corry_wang
34K Followers 268 Following Compute @ Anthropic | Formerly AI strategy @ Google and tech equity research @ Bernstein Research




Ke Li 🍁 @KL_Div
6K Followers 423 Following Assistant Professor of Computing Science @SFU. Ph.D. from @Berkeley_EECS and Bachelor's from @UofTCompSci. Formerly @GoogleAI and Member of @the_IAS.
Yaroslav Bulatov @yaroslavvb
11K Followers 1K Following @southparkcommons (early OpenAI, Google Brain, Meta) https://t.co/bxo5udY3ib https://t.co/SLix8Hrt4w https://t.co/Ur3GWKpmp6
Erik Meijer @headinthebox
36K Followers 0 Following
Science Banana @literalbanana
94K Followers 679 Following director of science programming for the Abstract Noun Abuse Prevention Task Force, a project of the Union of Concerned Anthropomorphic Fruit
spor @sporadica
125K Followers 1K Following CTO (Chief Taste Officer) @ your great-grandmother's palantir-inspired drone swarm startup ,, opinions my own
Steve Yegge @Steve_Yegge
41K Followers 14 Following I've been in the industry for O(40) years and have written O(1M) LOC. I don't think I'll ever write O(another) line again, but I'll be launching more than ever.

Ziming Liu @ZimingLiu11
14K Followers 881 Following Assistant Professor @ Tsinghua CollegeAI (incoming), Postdoc @ Stanford, PhD @ MIT, BS @ PKU. Physics of AI, interpretability, Structuralism, KAN
sysls @systematicls
62K Followers 62 Following All in @openforage. I thrived in all of the largest hedge funds managing systematic investment processes.
Samuel Albanie 🇬�... @SamuelAlbanie
8K Followers 1K Following frontier evals lead for gemini @GoogleDeepMind

Larry Dial @classiclarryd
2K Followers 41 Following Technical Staff at Open Athena, working on Marin
djma @davidma
10K Followers 2K Following

Muyu He @HeMuyu0327
3K Followers 307 Following Post-training @CollinearAI | Expert of mixtures, or 21st century schizoid man.
Isaac Liao @LiaoIsaac91893
1K Followers 123 Following ML PhD advised by @_albertgu at @mldcmu Previously: CS & Physics at @MIT. IPhO 2019 silver. Information compression and ARC-AGI
Chris McCormick @ChrisJMcCormick
782 Followers 65 Following Authored some of the most popular early tutorials and example code on Transformer architecture and fine-tuning.
Jing Yu Koh @kohjingyu
7K Followers 391 Following ML PhD @CarnegieMellon. Previously: computer use agents lead @ MSL TBD Lab, text-to-image generation @GoogleAI. Opinions my own. 🇸🇬
Albert Gu @_albertgu
21K Followers 77 Following assistant prof @mldcmu. chief scientist @cartesia_ai. leading the ssm revolution.



Lakshya A Agrawal @LakshyAAAgrawal
5K Followers 3K Following PhD @ UC Berkeley | @gepa_ai Creator | Created https://t.co/YxPZsXZJeS | AI4Code Research Fellow @MSFTResearch | Hobby Saxophonist

SzymonOzog @SzymonOzog_
3K Followers 289 Following Maximizing throughput at @poolsideai Educating people about GPUs at https://t.co/81rRJ4KoUt I like my tea green and my compute parallel
Brian Huang @brianryhuang
6K Followers 3K Following @GoogleDeepmind @antigravity | prev math and cs @mit
augustus odena @gstsdn
12K Followers 3K Following Something new. Previously: AI research at TBD Labs / Meta; cofounder at @AdeptAILabs; Invented Scratchpad / Chain-of-Thought; Google Brain
Cassandra Unchained @michaeljburry
1.9M Followers 33 Following Official X account for Michael Burry, MD, called "Cassandra" by Warren Buffett. Now on Substack with the full story.
Shane Gu @shaneguML
50K Followers 2K Following Gemini/Omni Thinking, Senior Staff AE @GoogleDeepMind. 🇯🇵-born 🇨🇳🇨🇦. ex: Gemini 1.5-3, GPT-4 @OpenAI, Google Robotics (JP: @shanegJP). Personal opinions.
Yacine Mahdid @yacinelearning
28K Followers 2K Following (neuro/ai) I make technical deep learning tutorials 👺
Eric W. Tramel @fujikanaeda
4K Followers 877 Following Research Scientist @ Nvidia. Ex: Synth Data @ Gretel & Unlearn, Federated Learning @ Amazon Alexa & Owkin. Postdocs @ INRIA & ENS. Views my own.
Joshua Achiam @jachiam0
27K Followers 1K Following Freedom, flourishing, and abundance. Chief Futurist @openai. Main author of https://t.co/cKuSh21yaz


Erik Schluntz @ErikSchluntz
11K Followers 301 Following Member of Technical Staff Co-founder at @CobaltRobotics Co-founder at Posmetrics (acquired) GoogleX, @SpaceX, @Harvard EE '15
Doug Lewin @douglewinenergy
21K Followers 4K Following Leading energy strategy and market development in Texas @Google. Powering breakthroughs and innovation at scale. Opinions stated here are my own. RT≠endorse
Golden Gate Institute... @GoldenGateInst
699 Followers 35 Following
You might like



















