
Say your training compute budget = ~1.5e13 FLOPs If your dataset has a gzip compressibility ratio of 0.14, you should *max out your param count* and skimp on dataset size But if your dataset is less compressible (gzip=0.61), *keep your model small* and train it on a ton of data

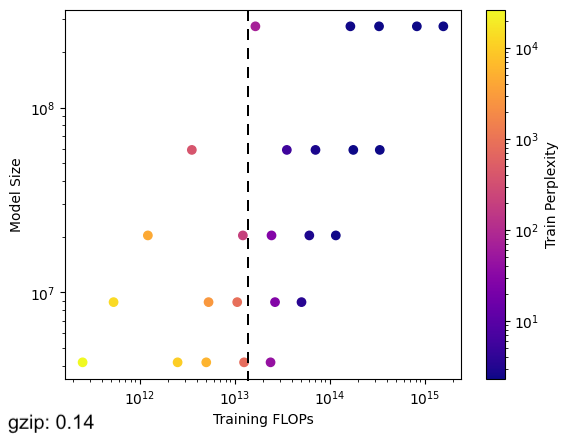
Say your training compute budget = ~1.5e13 FLOPs If your dataset has a gzip compressibility ratio of 0.14, you should *max out your param count* and skimp on dataset size But if your dataset is less compressible (gzip=0.61), *keep your model small* and train it on a ton of data https://t.co/hUwtTVvLqM

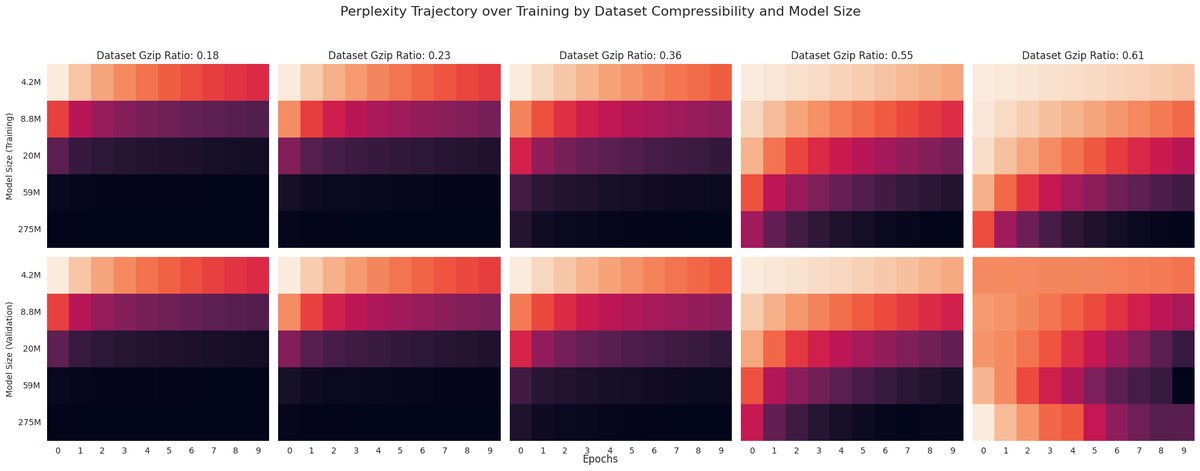
Here's a comparable (but data compressibility agnostic) visual from Chinchilla, I'm just not goated enough at matplotlib to plot those IsoLoss contours. I also haven't yet fit the actual scaling laws. Just been exploring visualizations + intuition last couple days lol sorry.



@khoomeik Can you elaborate? Intuitively, it feels like if your data is less compressible / harder to compress, you would need more parameters / model capacity to absorb the info entropy within the dataset. Why is the opposite true?

@khoomeik This is a really cool direction - I'm glad I get to say that I knew you before you became one of the godfathers of scaling :D

@khoomeik This is *incredibly* cool; I'm on the edge of my fucking seat. Also, love the apparent meta here: you can't really get scooped when you post your findings in real time!

@khoomeik That actually makes sense. I love this work.