
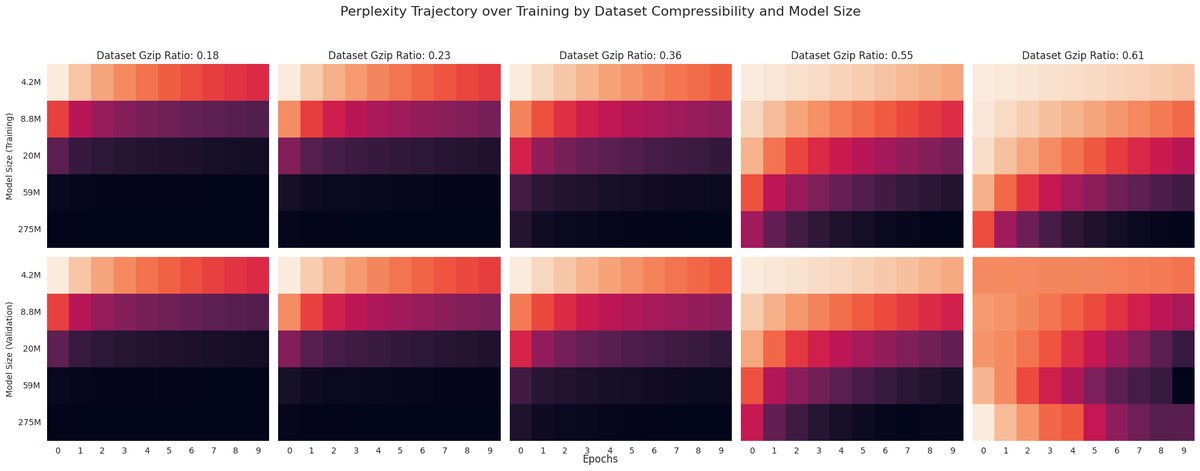
Language model scaling laws appear to be sensitive to data complexity (modulated by syntactic properties of a PCFG), and gzip effectively predicts the impact of these dataset-specific scaling properties.

everyone wants the visuals and no one wants the data huh? classic
everyone wants the visuals and no one wants the data huh? classic


@khoomeik Wait, please correct me if I'm wrong - you are implying the model's quality is directly proportional to the gzip compressibility of the dataset used to train the model relative to the models and datasets of the same weight and size class?

@khoomeik @Yampeleg @BrandesNadav Yet another point for our using Uniref50 in #Proteinbert (and others following the trick) :D
