

!p#a$r@i @dfmrrd
Joined April 2008-
Tweets558
-
Followers56
-
Following302
-
Likes29K

This is how the Romans moved heavy blocks.
@billmaher I’ve been a longtime listener for over 10 years, and I feel deeply disappointed and betrayed. Your lack of compassion toward Palestinians is disheartening. I worry that this hostility will define how people remember you.
Pulkit and I had many chats since the start of my PhD of how models should intimately understand force and physics. I always thought this is the right technical bet to make and now Pulkit + Team is paving the path to bring this to life!

Eka means unity -- “one,” in Sanskrit and “first” in Finnish. We’re building intelligence for the physical world in its native language: forces. Until now, robotics faced a tradeoff — generality or speed. The real world requires both. Robotics also faced a data problem. Our

Yesterday, Andrej Karpathy gave a 30-minute Sequoia masterclass on agentic engineering. This is the serious layer above vibe coding. He explained: - LLMs as ghosts - The app that shouldn't exist - Outsource thinking, not understanding 12 lessons that will blow your mind: 🧵

Karpathy told Dwarkesh that a 1 billion parameter model, trained on clean data, could hit the intelligence of today's 1.8 trillion parameter frontier. That is a 1,800x compression claim. The math behind it is more defensible than it sounds. When researchers at frontier labs look at random samples from their training corpus, they see stock ticker symbols, broken HTML, forum spam, autogenerated gibberish. Not Wikipedia. Not the Wall Street Journal. The actual pretraining dataset is mostly noise, and the model is burning parameters to vaguely remember all of it. One estimate pegs Llama 3's information compression at 0.07 bits per token. Well-structured English carries around 1.5 bits per token of real information. The trillion-parameter model is holding a roughly 5% resolution image of the internet it trained on. So when a lab ships a 1.8 trillion parameter model, the overwhelming majority of those weights are handling rough memorization. They are compression overhead for a noisy training set, taking up capacity that could be doing reasoning instead. Karpathy's proposal is to separate the two. Build a cognitive core: a small model that contains only the algorithms for reasoning and problem-solving, stripped of encyclopedic memorization. Pair it with external memory the model queries when it needs a fact. A 1 billion parameter reasoner plus retrieval beats a 1.8 trillion parameter model trying to do both. The data already supports this direction. GPT-4o runs at roughly 200 billion parameters and outperforms the original 1.8 trillion GPT-4. Inference costs for GPT-3.5 level performance fell 280x between 2022 and 2024, driven almost entirely by smaller, cleaner, better-architected models. The trend line is pointing where Karpathy says it should. The real implication for anyone tracking the AI trade: data quality is the actual constraint. The companies winning the next phase will be the ones who figured out what to train on, and what to throw away.

🚨 Nvidia CEO Jensen Huang: “The narratives of AI destroying jobs is not going to help America — It's false … Somebody said that AI Is going to destroy all of the software engineering jobs … We now have agentic AI inside Nvidia … The software engineers are busier than ever.”

New course: Spec-Driven Development with Coding Agents, built in partnership with @jetbrains, and taught by @paulweveritt. Vibe coding is fast, but often produces code that doesn't match what you asked for. This short course teaches you spec-driven development: write a detailed spec defining what to build, and work with your coding agent to implement it. Many of the best developers already build this way. A spec lets you control large code changes with a few words, preserve context across agent sessions, and stay in control as your project grows in complexity. Skills you'll gain: - Write a detailed specification to define your mission, tech stack, and roadmap, giving your agent the context it needs from the start - Plan, implement, and validate features in iterative loops using a spec as your agent's guide - Apply the same repeatable workflow to both new and legacy codebases - Package your workflow into a portable agent skill that works across agents and IDEs Join and write specs that keep your coding agent on track! deeplearning.ai/short-courses/…

In 1945, a student asked C.R. Rao in a classroom at the Indian Statistical Institute, “How much information can we truly extract from a tiny bit of data?” Rao went home, worked through the night, & derived a fundamental inequality that sets the theoretical limit on how precisely we can estimate any parameter from data. This is now known as the Cramér-Rao Inequality (or Cramér-Rao Lower Bound). It tells engineers, physicists, & data scientists worldwide, from those building GPS systems to those searching for the Higgs boson (God Particle)...the absolute maximum precision they can ever achieve with unbiased estimators. It remains 1 of the most important speed limits in information theory & statistics.


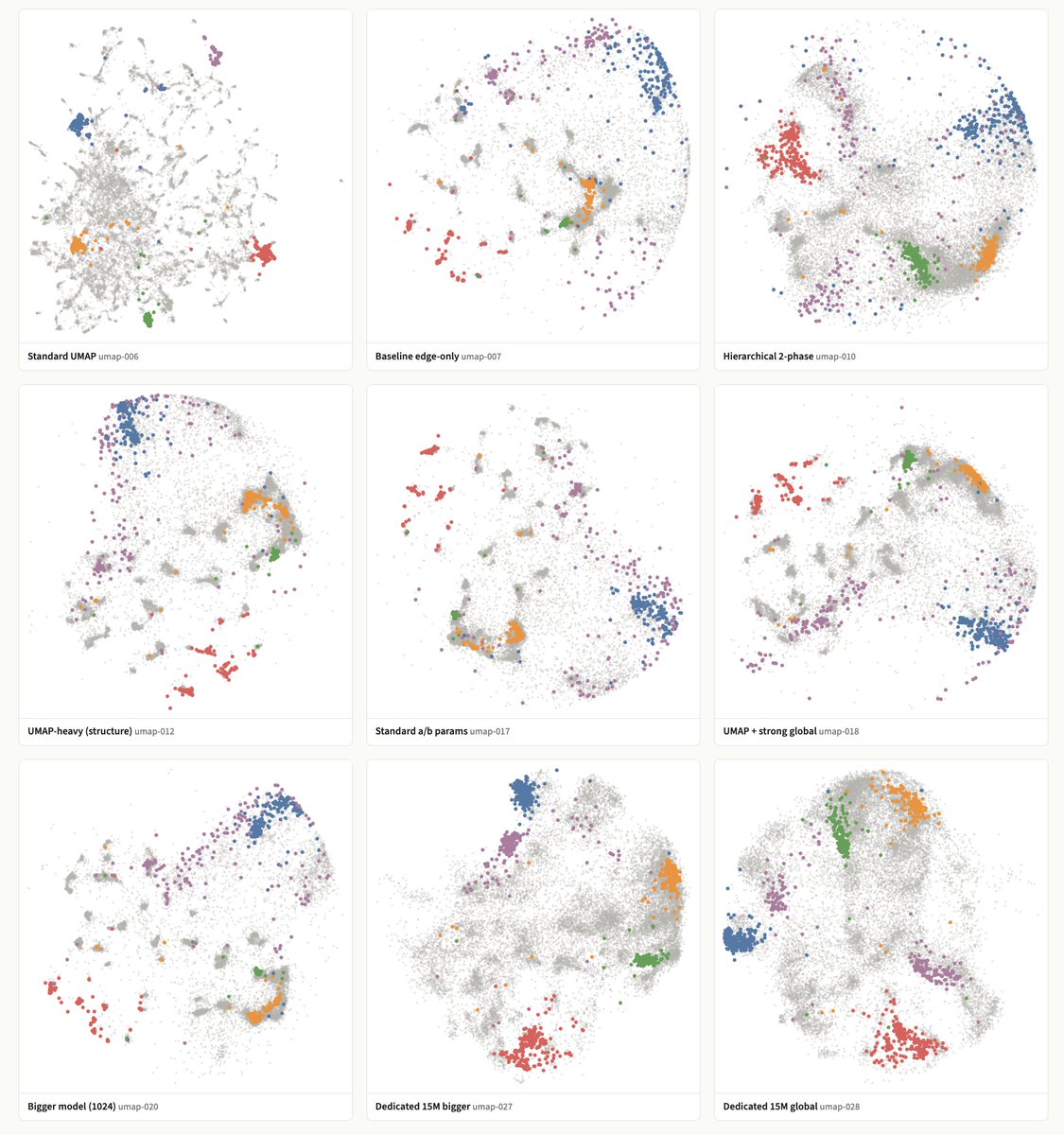
trying autoresearch on parametric umap (clusters determined by evoc on embeddings)

After much reflection, I have decided to resign from my position as Director of the National Counterterrorism Center, effective today. I cannot in good conscience support the ongoing war in Iran. Iran posed no imminent threat to our nation, and it is clear that we started this war due to pressure from Israel and its powerful American lobby. It has been an honor serving under @POTUS and @DNIGabbard and leading the professionals at NCTC. May God bless America.


You're in a Research Scientist interview at DeepMind. The interviewer asks: "Our investors want us to contribute to open-source. Gemini crushed benchmarks. But we'll lose competitive edge by open-sourcing it. What to do?" You: "Release a research paper." Here's what you missed: LLMs today don't just learn from raw text; they also learn from each other. For example: - Llama 4 Scout & Maverick were trained using Llama 4 Behemoth. - Gemma 2 and 3 were trained using Gemini. Distillation helps us do so, and the visual explains 3 popular techniques. 1️⃣ Soft-label distillation Generate token-level softmax probabilities over the entire corpus using: - A frozen pre-trained Teacher LLM. - An untrained Student LLM. Train the Student LLM to match the Teacher's probabilities. In soft-label distillation, access to Teacher's probabilities gives max knowledge transfer. But you must have access to the Teacher’s weights to get the probability distribution. Even if you have access, there's another problem! Say your vocab has 100k tokens and data has 5 trillion tokens. Storing softmax probabilities over the entire vocab for each input token needs 500M GBs of memory under fp8 precision. The second technique solves this. 2️⃣ Hard-label distillation - Use the Teacher LLM to get the output token. - Get the softmax probs. from the Student LLM. - Train the Student to match Teacher's output. DeepSeek-R1 was distilled into Qwen & Llama using this technique. 3️⃣ Co-distillation - Start with an untrained Teacher and Student LLM. - Generate softmax probs over the current batch from both models. - Train the Teacher LLM on the hard labels. - Train the Student LLM to match softmax probs of the Teacher. Meta used co-distillation to train Llama 4 Scout and Maverick from Llama 4 Behemoth. Of course, during the initial stages, soft labels of the Teacher LLM won't be accurate. That is why Student LLM is trained using both soft labels + ground-truth hard labels. ____ Find me → @_avichawla Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.

You're in an ML Engineer interview at Amazon. The interviewer asks: "You’ve trained a new recommendation model. How do you make sure it’s ready to replace the old one?" You reply: "I’ll compare metrics on validation and test sets." Interview over. Here’s what you missed: The issue is that, despite rigorously testing an ML model locally (on validation and test sets), it could be a terrible idea to instantly replace the previous model with the new model. This is because it is difficult to replicate the exact production environment and conditions locally, and justify success with val/test accuracies. A more reliable strategy is to test the model in production (yes, on real-world incoming data). While this might sound risky, ML teams do it all the time, and it isn’t that complicated. Note: > Legacy model: The existing model. > Candidate model: The new model. Here are four common ways to do it: 1️⃣ A/B testing Distribute the incoming requests non-uniformly between the legacy model and the candidate model. This limits the exposure of the candidate model to avoid any potential risks. So, say, 10% requests go to the candidate model, and the rest are still served by the legacy model. 2️⃣ Canary testing A/B testing typically affects all users since it randomly distributes “traffic” to either model (irrespective of the user). In canary testing, the candidate model is exposed to a small subset of users in production and gradually rolled out to more users if its metrics signal success. 3️⃣ Interleaved testing This involves mixing the predictions of multiple models in the response. For instance, in Amazon's recommendation engine, some recommendations can come from the legacy model, while some can be produced by the candidate model. Alongside, we can log the downstream success metrics (click-rate, watch-time, reported-as-not-useful-recommendation, etc.) for comparison later. 4️⃣ Shadow testing All of the above techniques affect some (or all) users. Shadow testing (or dark launches) lets us test a new model in a production environment without affecting the user experience. The candidate model is deployed alongside the existing legacy model and serves requests like the legacy model. However, the output is not sent back to the user. Instead, the output is logged for later use to benchmark its performance against the legacy model. We explicitly deploy the candidate model instead of testing offline because the exact production environment can be difficult to replicate offline. Shadow testing offers risk-free testing of the candidate model in a production environment. But one caveat is that you can’t measure user-facing metrics in shadow testing. Since the candidate model’s predictions are never shown to users, you don’t get real engagement data, like clicks, watch time, or conversions. And this is exactly how top ML teams at Netflix, Amazon, and Google roll out new models safely. They never flip the switch all at once. They test in production, observe, compare, and then promote the model to 100% traffic. Of course, alongside all this, you would also measure latency, throughput, resource usage, and downstream success metrics. A model that’s 2% more accurate but 3× slower isn't desired from a user experience standpoint. Over to you: How do you test your models before replacing the old ones? ---- Find me → @_avichawla Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.


You’re in an ML Engineer interview at Google. Interviewer: We need to train an LLM across 1,000 GPUs. How would you make sure all GPUs share what they learn? You: Use a central parameter server to aggregate and redistribute the weights. Interview over. Here’s what you missed:

MIT researchers proposed something called the "platonic representation hypothesis" and it's one of the most fascinating ideas in ai right now 🤯 the core claim: as neural networks get bigger and train on more data, their internal representations are converging. vision models, language models, different architectures, different training objectives. they're all slowly approximating the same underlying model of reality. think of it like this. imagine a hundred cartographers mapping the same territory using completely different tools. one uses satellites, another uses sonar, another walks on foot. at first the maps look nothing alike. but as the tools improve and the coverage increases, the maps start agreeing. not because the cartographers coordinated. because the territory is real. Huh, Cheung, Wang, and Isola at MIT tested this across 78 vision models with different architectures, objectives, and training data. the result: as models scale, their representation kernels (basically how they measure similarity between data points) converge toward the same structure. the practical implications are wild if this holds. you could translate between models instead of treating each as a sealed black box. interpretability work on one system could transfer to another. alignment could happen at the representation level, not just by policing outputs. but here's where it gets honest. the best alignment score they measured (using DINOv2) was 0.16. perfect alignment would be 1.0. so we're seeing a trend toward convergence, not convergence itself. there's a massive gap between "representations are becoming more similar" and "representations are the same." also: different modalities genuinely capture different information. the text "apple" doesn't tell you if it's red or green. an image does. a symphony's emotional texture doesn't fully translate to text. there are real information asymmetries that might set hard limits on how far convergence can go. and the elephant in the room: sociological bias. we're all training on similar internet data, using similar architectures (transformers), optimizing similar objectives. is convergence evidence of a deep truth about reality, or evidence that the ai field has a monoculture problem? if every model is a transformer trained on web text, of course they'll agree. that's not philosophy. that's homogeneity. the authors are refreshingly upfront about this. they frame it as a position paper, not a proof. they discuss counterexamples. they acknowledge that domains like robotics show no convergence at all yet. the philosophical question underneath is genuinely compelling though. if sufficiently capable learners trained on different data independently discover the same representational structure, that suggests something real about the territory being mapped. maybe meaning isn't just a human convention. maybe there are natural coordinates in reality that strong enough learners keep rediscovering. or maybe we're just reading patterns into a field that hasn't diversified its methods enough to test the hypothesis properly. either way, this paper reframes how we think about what models are actually doing when they learn. they're not just memorizing patterns. they might be recovering structure. the honest take: convergence is real. the platonic interpretation is beautiful. but 0.16 out of 1.0 means we're writing philosophy on top of a trend line, not a theorem.


Mathematician Terence Tao admitted that GPT-5.2 found a mistake in his work: "ah, gpt (gpt5.2) was right about a fatal sign error in my small-primes step, so i checked Hildebrand and used his log-concavity trick for the Dickman function" tao recently said that AI is no longer just hype when it comes to mathematical discovery


What happens when we're no longer limited by intelligence, but agency? We hosted a panel with @soumithchintala, @srush_nlp, & @jefrankle at @southpkcommons on agentic frontiers. Watch the full conversation now.
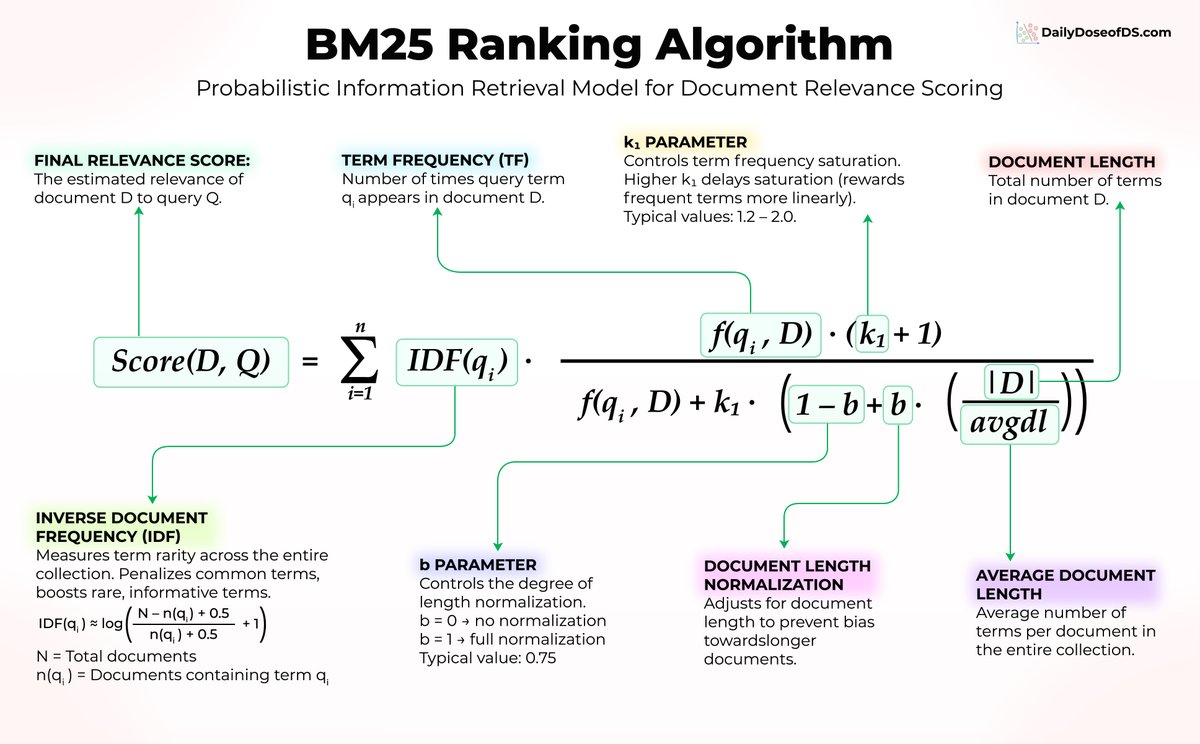
Vector search is not always the answer. A 30-year-old algorithm with zero training, zero embeddings, and zero fine-tuning still powers Elasticsearch, OpenSearch, and most production search systems today. It's called BM25, and it's worth understanding why it refuses to die. Let's say you're searching for "transformer attention mechanism" in a library of ML papers. BM25 scores documents using three core ideas: 1) Word rarity matters more than word frequency Every paper contains "the" and "is" so those words carry no signal. But "transformer" is specific and informative, so BM25 gives it a much higher weight. In the formula, this is captured by IDF(qᵢ). 2) Repetition helps, but with diminishing returns If "attention" appears 10 times in a paper, that's a strong relevance signal. But the jump from 10 to 100 occurrences barely moves the score. BM25 applies a saturation curve controlled by f(qᵢ, D) and the parameter k₁, preventing keyword stuffing from gaming the results. 3) Document length gets normalized A 50-page paper will naturally contain more keyword hits than a 5-page paper. BM25 adjusts for this using |D|/avgdl, controlled by parameter b, so longer documents don't dominate the rankings just because they have more text. Three ideas. No neural networks. No training data. Just elegant math that has stood the test of time. Here's the part most people overlook: BM25 excels at exact keyword matching, which is something embeddings genuinely struggle with. When a user searches for "error code 5012" vector search might return semantically similar error codes. BM25 will surface the exact match every time. This is exactly why hybrid search has become the default in top RAG systems. Combining BM25 with vector search gives you semantic understanding AND precise keyword matching in a single pipeline. So before you throw GPUs at every search problem, consider that BM25 might already solve it, or at the very least, make your semantic search significantly better when the two are combined.

This was asked in a Google interview recently. You deployed a new feature to production, but 30% of users are seeing stale data while 70% see fresh data. How will you debug and fix this issue?

Very common interview question asked these days: How do you handle token expiry without asking the user to log in again?

California's Central Valley produces 80% of the world's almonds. Each almond requires 3.2 gallons of actual irrigation water to grow. Not rainfall. Actual tap water pumped from aquifers. One gallon of almond milk requires 162 gallons of irrigation water. Compare that to dairy milk at 8 gallons of tap water per gallon, with the rest being rainfall that falls on pasture anyway. But here's where it gets properly grim. Almonds bloom for exactly three weeks in February. During those three weeks, California needs every pollinating bee in North America transported to the Central Valley or the crop fails entirely. Commercial beekeepers truck in 31 billion honeybees. That's two-thirds of America's entire managed bee population, all concentrated in one valley for three weeks. The bees are packed into trucks, driven across the country, dumped into almond groves drenched in pesticides, worked to exhaustion, then packed up and shipped to the next crop. The mortality rate is catastrophic. Beekeepers report losing 30 to 50% of their hives annually. That's billions of bees dead. Not from natural causes. From being used as disposable pollination machines for your almond milk. The pesticides don't help. Almond groves are sprayed with neonicotinoids which scramble bee navigation systems, fungicides which weaken their immune systems, and herbicides which eliminate the wildflowers they'd normally forage on between almond blooms. Meanwhile the aquifer depletion is permanent. The Central Valley has sunk 28 feet in some areas from groundwater extraction. That water took 10,000 years to accumulate. It's being drained in decades for almond milk. Your vegan latte killed more bees and used more water than a year's worth of dairy milk. But it's got "plant-based" on the label so you're definitely saving the planet.


This is absolutely shameful. Agents of a federal agency unnecessarily escalating, and then executing a defenseless citizen whose offense appears to be using his cell phone camera. Every person regardless of political affiliation should be denouncing this.
Drop Site obtained harrowing footage of the latest killing which appears to be from the perspective of the woman in pink filming from the sidewalk



cammy deadpan @MMullen2019
89 Followers 2K Following heart on my sleeve, glitter on my timeline 💖 follow back

Qeefveeg @Qeefveeg130
114 Followers 2K Following
Lashew @Lashew1rPJHY
26 Followers 2K Following
Tristan Snell @TristanSnell
577K Followers 223K Following Lawyer, commentator, fighter for democracy. Prosecuted Trump University @ NY AG. Substack: https://t.co/9iRTNuAbIH. Host of the Tristan Snell Show on Apple + Spotify.
My official @myfanofficial11
67 Followers 2K Following Investable is profitable, make your success speak.

Forget @forget19718
67 Followers 3K Following
Zoe @Zoe264758644301
59 Followers 4K Following
Thouthou @Thouthou993355
52 Followers 4K Following
E_den @Eden4819877407
38 Followers 4K Following
Thoushe @Thoushe113567
13 Followers 1K Following
Teshy @Teshy27626
77 Followers 5K Following




Harrison George @Harriso30425272
162 Followers 85 Following Doctors believe that comforting words are sometimes more helpful than good medicine
Emma johanna @EzehLenora
198 Followers 2K Following Divorced with kids,Forex and crypto expert trader with over 3000 students/clients. #Bitcoininvestments #Bitcoin #BTC
Lucy @mazasheikh
174 Followers 4K Following Single, enjoys travel, fitness, golf, wine, independent investor Graduated from Durham University, London, UK Believes that useful trading is a gold mine
Grace. Kelly @GennieVale93318
121 Followers 2K Following looking for someone who is completely honest and sincere in his words and feels someone to whom i can give my heart and soul, someone i can call my life partner
Zeeshan Ahmed @Zeeshan97291
366 Followers 5K Following
Cherry @BeeAnran36
64 Followers 925 Following Life is giving, giving is forever, it is not wealth that makes us valuable, but who we become becomes valuable.

Denise Rojas @DeniseR11635855
95 Followers 3K Following Things Go Better With Recommend the Best Games to You.
Felicia Mitchell @Felicia42620894
87 Followers 2K Following #EmbraceTheDarkness 라는 게임의 커뮤니티 사이트, # TI10다.

@EGGERS_ANDREA_ @EGGERS_ANDREA_
1K Followers 4K Following Hacked at 45k, Cryptocurrency Investment coach, Philanthropist, Educator, God Fearing Mother, 📊📊Specialising in Crypto Order Flow,


Kumaran Rajaram @tkums
11 Followers 44 Following
Marlene _Li @Jennyros143
44 Followers 297 Following My own clothing company. I'm partner in this company, Azalea, my founder partner.


Carles Mateo @carlesmateo_com
180 Followers 1K Following Engineer. Open Source creator. Book writer (tech and novel). Programming teacher. Radio presenter. Entrepreneur. Cloud Architect. SDM. SRE. Opinions are my own

Tori @VictorH98416144
645 Followers 2K Following #BLM 🌈Democrat for life. Mental illness real y’all let’s treat it as such and drop the stigma especially in the Black communities and churches.
Mary Bailey @MaryBai27454703
10 Followers 154 Following

wonderbread2021 @wonderbread2021
15 Followers 152 Following If you will not choose between two lesser evils then you will be governed by the greater one.

Acrobatica Spider Acc... @Spider_Access
77 Followers 54 Following The Leading Access Solution Service provider in GCC 🧗🏻 #spideraccess #ropeaccess ☎️ +971 52 726 3167 / +971 4 236 0356 📩 [email protected]

MEAT THE FUTURE @MTFFilm
2K Followers 2K Following Imagine a world where real meat is a climate solution, without the need to harm animals. Watch #MeatTheFuture on demand in the US & select territories.

Mohamed Awal @Kanemary12345
171 Followers 3K Following


sarah @sahouraxo
716K Followers 608 Following Independent Lebanese geopolitical commentator. Join my ONLY Telegram channel: https://t.co/v4fQXfq2hQ
Apoorva Panidapu @apoorvapanidapu
1K Followers 156 Following math, cs, ecology, & political science @stanford
Eric Jang @ericjang11
134K Followers 4K Following
Krish Ashok @krishashok
149K Followers 657 Following Techie (https://t.co/dULL1kpela), Author of Masala Lab (https://t.co/MdeRPLmgVz…), Musician (https://t.co/9sVjqvRpa4)
Genesis AI @gs_ai_
11K Followers 0 Following Genesis AI is a global full-stack robotics company building general-purpose robots with human-level intelligence.
The Happy Path @The_HappyPath
976 Followers 167 Following Quick software engineering explainers for things you should've googled by now
Prem Thakker @prem_thakker
94K Followers 2K Following reporter @zeteo_news | any tips or info you'd like to share? text me on signal: premthakker.35 | or [email protected]

Johann Spischak @SDGMasterglass
30K Followers 4K Following Langzeitarchivierung, Audioforensik und Mastering.
Emma Vigeland @EmmaVigeland
306K Followers 2K Following @majorityfm co-host. Live Monday-Friday, 12 PM ET. @ESVNShow. New York sports fan who tweets about it. Free Palestine 🇵🇸
Dave W Plummer @davepl1968
103K Followers 85 Following Hi! I'm Dave Plummer. You might remember me from such Windows components as Task Manager, Windows Pinball, Calc, ZIPFolders, Product Activation, etc. Cheers!
Saikat Chakrabarti @saikatc
80K Followers 1K Following
sarah guo @saranormous
145K Followers 3K Following startup investor/helper, founder @conviction. accelerating AI adoption, interested in progress. tech podcast: @nopriorspod
Mayank Mishra @MayankMish98
2K Followers 558 Following Model Architecture & Pretraining | ex pretraining lead for Granite Models @IBMResearch
Shivam Duggal @ShivamDuggal4
1K Followers 427 Following PhD Student @MIT | Prev: Carnegie Mellon University @SCSatCMU | Research Scientist @UberATG
Yikang Shen @Yikang_Shen
2K Followers 469 Following CEO at Learning Machine. ex MTS @xAI. ex Staff RS @IBM. PhD @Mila. Ordered Neurons, Mixture of Attention Heads, JetMoE, stick-breaking attention, DeltaNet.
Raj Dabre @prajdabre
22K Followers 1K Following Senior Research Scientist - @google, Adjunct Faculty - @iitmadras, Ex: @NICT_Publicity @iitbombay
Rohan Paul @rohanpaul_ai
150K Followers 7K Following Compiling in real-time, the race towards AGI. The Largest Show on X for AI. 🗞️ Get my daily AI analysis newsletter to your email 👉 https://t.co/6LBxO8215l
Rohan Pandey @khoomeik
42K Followers 3K Following descending cross-entropy to ascend entropy @PeriodicLabs || prev research @OpenAI @CarnegieMellon '23

Emerald Robinson ✝�... @EmeraldRobinson
918K Followers 9K Following The Savage Queen of Twitter. Host @AbsoluteWithE on @realLindellTV. Ex-Newsmax & Ex-OANN WH Correspondent. Read me at: https://t.co/cxBgvYc7eC
idan shenfeld @IdanShenfeld
2K Followers 188 Following PhD student @MIT | Prev student researcher @GoogleDeepMind
Former Congresswoman ... @FmrRepMTG
5.4M Followers 940 Following Christian, Mother, Business Owner, and Former Congresswoman of Georgia’s 14th District |AMERICA FIRST AMERICA ONLY 🇺🇸
Pratyusha Sharma @pratyusha_PS
5K Followers 467 Following Science ⇌ Deep Learning. Incoming Asst. Professor at NYU (@NYU_Courant & @NYUDataScience). Sr Researcher at @Microsoft. PhD @MIT_CSAIL.
Songlin Yang @SonglinYang4
18K Followers 3K Following pretraining @thinkymachines. Prev. PhD @MIT_CSAIL. she/her/hers
Danqi Chen @danqi_chen
18K Followers 830 Following Associate professor @princetonPLI @PrincetonCS MoTS @thinkymachines Previously: @facebookai, @stanfordnlp, @Tsinghua_Uni
Karthik Narasimhan @karthik_r_n
5K Followers 468 Following Professor@PrincetonCS, ex @OpenAI, @SierraPlatform, @MIT_CSAIL, @iitmadras Work: GPT, ReAct, Tree-of-Thoughts, SWE-Bench/Agent, TAU-bench, GEO



⿻ Andrew Trask @iamtrask
82K Followers 1K Following i build & teach AI with attribution-based control @openminedorg @GoogleDeepMind @OxfordUni
Albert Gu @_albertgu
21K Followers 77 Following assistant prof @mldcmu. chief scientist @cartesia_ai. leading the ssm revolution.
Thomas Massie @RepThomasMassie
1.8M Followers 25K Following U.S. Representative KY4, Engineer, Farmer, Inventor. 30 patents. Appalachian American. MIT SB93 SM96 #sassywithmassie #politicalsciencedenier pronoun: Pappaw

Ryan Grim @ryangrim
530K Followers 12K Following Reporter at @DropSiteNews - Author of "We've Got People,” “The Squad,” and “This Is Your Country On Drugs.” Co-host of Breaking Points. Signal: cherrygarcia.01
Krystal Ball @krystalball
625K Followers 5K Following Krystal Kyle & Friends. Breaking Points. Ella, Lowell and Ida Rose's Mama!

jasper nathaniel @infinite_jaz
64K Followers 1K Following reporting on the occupied West Bank. subscribe to my substack for stories you won’t find anywhere else 👇
AF Post @AFpost
510K Followers 0 Following News and alerts from around the world, from an America First perspective. Not affiliated with any organization, podcast, or activist.

Ro Khanna @RoKhanna
459K Followers 3K Following Team America. New Economic Patriotism: Good Jobs, Low Costs, No Dumb Wars. Marshall Plan for America. M4A. $10 day childcare. Tax ultra wealth. (650) 999-9610
Shengjia Zhao @shengjia_zhao
52K Followers 235 Following Chief Scientist @ Meta MSL. Formerly MTS @ OpenAI, PhD @ Stanford. I train models. All opinions my own.
The Nobel Prize @NobelPrize
1.3M Followers 492 Following The official feed of the Nobel Prize @NobelPrize #NobelPrize
Akarsh Kumar @akarshkumar0101
2K Followers 689 Following PhD Student @MIT_CSAIL RS Intern @SakanaAILabs RL, Meta-Learning, Emergence, Open-Endedness, ALife
Tristan Snell @TristanSnell
577K Followers 223K Following Lawyer, commentator, fighter for democracy. Prosecuted Trump University @ NY AG. Substack: https://t.co/9iRTNuAbIH. Host of the Tristan Snell Show on Apple + Spotify.
Aravind @aravind
302K Followers 385 Following I talk about issues long before they happen. Now and then in touch with Turiya. I post conspiracies and nothing I say is real. Don't believe anything I post.
Turing Post @TheTuringPost
86K Followers 9K Following On X we surface the AI research that matters and explain the ideas behind it. In the newsletter, we connect the dots between AI’s past, present, and future ⬇️
Noam Brown @polynoamial
136K Followers 916 Following Researching reasoning @OpenAI | Co-created Libratus/Pluribus superhuman poker AIs, CICERO Diplomacy AI, and OpenAI o-series 🍓 reasoning models
New York University @nyuniversity
203K Followers 1K Following The official Twitter account of New York University—in and of the city; in and of the world. Managed by the Office of Public Affairs: https://t.co/ZSbBEceRf7
Irmak Guzey @irmakkguzey
1K Followers 237 Following PhD student at @CILVRatNYU. On a mission to make robotic hands as dexterous as human ones! 🤖✋. Previously: Intern @AIatMeta. (she/her)You might like








