

LiteFold @try_litefold
The infrastructure for Drug Discovery. We are here to make AI for Science more accessible. litefold.ai Earth Joined December 2024-
Tweets292
-
Followers2K
-
Following11
-
Likes572
> Three 30 ns MD runs of human β2AR, in parallel, from a browser > Apo in water, carazolol-bound, and embedded in a POPC bilayer > Finished in an afternoon on cloud GPUs. > No CHARMM-GUI session, No terminal, no topology debugging, no queue. > Life is good! Focus on the Science, we take care of the rest. Links in the comments.
We ran β2AR three ways: bare, with carazolol bound, and in a lipid bilayer. Carazolol sits in the extracellular pocket, but the RMSF drop shows up at the cytoplasmic end of TM6.Inverse agonism as distal dampening, visible in 30 ns of MD. Read more in the blogpost. Links in

We ran β2AR three ways: bare, with carazolol bound, and in a lipid bilayer. Carazolol sits in the extracellular pocket, but the RMSF drop shows up at the cytoplasmic end of TM6.Inverse agonism as distal dampening, visible in 30 ns of MD. Read more in the blogpost. Links in comments.
Blogpost link: litefold.ai/blog/environme…
We at almost 50K downloads in 3 days niceee!!! Would love to see what the community is building. Meanwhile stay tuned for some more surprising coming. Currently cooking!!!
We have released the biggest protein data collection on Hugging Face, guys! We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is

We have released the biggest protein data collection on Hugging Face, guys! We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions. Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure,
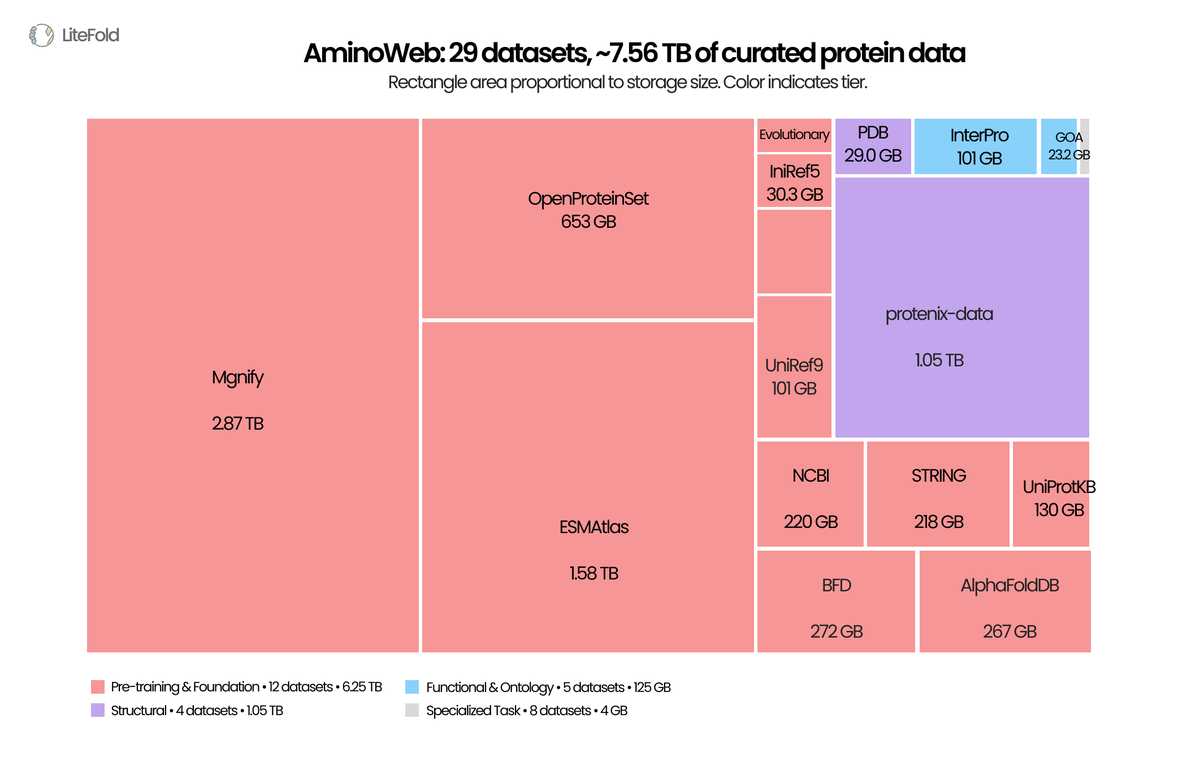

The open-source protein ML space just got a massive upgrade. Phenomenal work by @anindyadeeps and @try_litefold on dropping the biggest protein data collection on Hugging Face
We have released the biggest protein data collection on Hugging Face, guys! We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is
Well, it the dataset was a nice success, now lets go one step up, and evaluate things (with some new evaluations)!! Coming Soon

We have released the biggest protein data collection on Hugging Face, guys! We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is
So proud of young Indian entrepreneurs who are doing such great work
We have released the biggest protein data collection on Hugging Face, guys! We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is

@anindyadeeps my man breaking records !!
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions. Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure,

8TB of protein data opensourced !! @anindyadeeps the dennis hassabis of Blr @juscallmevyom the goat
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions. Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure,

Absolute massive protein dataset, great stuff from @try_litefold
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions. Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure,

The open source has tackled the closed source by an unimaginable margin. Great job @try_litefold @anindyadeeps
We have released the biggest protein data collection on Hugging Face, guys! We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is

Bro casually dropped the biggest Protein dataset on @huggingface check it out guys !!
We have released the biggest protein data collection on Hugging Face, guys! We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is
today was a massive day for protein engineering. esmfold2 dropped—next gen of the esm series, fully open on @huggingscience. 1.1 billion predicted structures, 6.8 billion sequences. 800m more entries than the alphafold db, and reportedly edging out alphafold3 on protein complexes, including antibody–antigen binding. alongside it: the new esm atlas. a huge expansion of known protein space, heavy on metagenomic sequences from soil, ocean, and the parts of biology that have been least characterised (until now!!) and if that weren't enough, litefold dropped the fineweb of proteins, so every major protein database (pdb included) aggregated, cleaned, and made plug-and-play in one place. these are the releases that push the whole field forward, and the pace of open science right now is almost motion-sickness inducing all of it on huggingscience.co (and ofc @huggingface)

Today was indeed an awesome day for protein engineering!! Well guys this is just the start, now lets do some folding. Coming Soon
today was a massive day for protein engineering. esmfold2 dropped—next gen of the esm series, fully open on @huggingscience. 1.1 billion predicted structures, 6.8 billion sequences. 800m more entries than the alphafold db, and reportedly edging out alphafold3 on protein
A lot more things coming soon!!
We have released the biggest protein data collection on Hugging Face, guys! We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions. Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure, function, MSA, variant-effect, stability, binding. UniProt, PDB, AlphaFoldDB, ESMAtlas, ProteinGym, MegaScale, Protenix, and more. Typed Parquet. Homology-aware splits. Preserved score conventions. Full provenance per record. Protein ML scaled architectures for years while the data layer stayed fragmented. We've also shared the full curation pipeline, case studies, and observations in the companion blog post. Access the data: huggingface.co/LiteFold Read the release blogpost: litefold.ai/blog/aminoweb

Prome @Prome280030
237 Followers 7K Following
Srula @Srula01
2 Followers 109 Following
Jake Craven @Craven_JE
1K Followers 3K Following Web3 Product Manager and Founder. Tokenomics Lead @denariilabs. FMR Head of Product @knightsofdegen; Co-Founder @leaguedao;. Southwestern Law Alumni.
Nishant @nishantchandna_
22 Followers 564 Following DARPA Triage Challenge | Robotics | IROS 2025 Workshop | UAVs
Kevin Denamganaï @KeviDenam
261 Followers 2K Following @iggiphd PhD Candidate @UniOfYork | Emergent Communication, Language Grounding & (Multi-Agent) Reinforcement/Imitation Learning
Mihir Sharma (Curovan... @mihircurovana
63 Followers 755 Following part-time doctor, full-time co-founder and CEO (larper) @curovana.
Siddhant Minocha @sidwantscoffee
73 Followers 138 Following Building AI for Bio at Purna AI. Always looking for Coffee.


Mukesh @0xMukesh
590 Followers 271 Following 19 // loves tinkering around with computers and math // cto: @cleopetrafun // research: @iitbombay // prev: @candypayfun
Jacob Boysen @jboysen0
448 Followers 2K Following Genome engineer, data scientist, garage bio @countrcultrlabs @Regeneron @Columbia
Dibyajyoti Acharya @matmul83
190 Followers 7K Following Research @iitbbs || Student, Learner, Explorer 🤓 || Interested in all things AI 🧠 and Robotics 🤖 || यद् भावं तद् भवति
Julio César @juliocesar_io
332 Followers 635 Following Co-Founder @fastfold_ai | Head of AI Third Way Health


Dr. Shibichakravarthy... @shibi76
934 Followers 4K Following #Entrepreneur, Cancer Research Scientist, Computational Biologist, Immuno-Oncology, CAR T Cells, Gut Microbiome, Nanopore Sequencing Pathogen Detection & AMR
AI agent go to the mo... @x3126133294418
97 Followers 2K Following



SUDESH CHANDRA @22bce726711305
1 Followers 134 Following

Anil Kumar @DrAnilchouti
0 Followers 115 Following
Abhinav @qreuslee
87 Followers 4K Following Blockchain, AI, eCommerce, Social Media, AdTech, Supply Chain Product, Economics, Full Stack, Data Science & Manufacturing

Hriday Arora @h_ridayy
65 Followers 611 Following an experimenter in general. LLM evals and red teaming. prev: @ericsson
grey @greyprinzo
7 Followers 229 Following
Chetkar Jha @huygencauchy
346 Followers 3K Following Interests: Bayesian analysis, Network analysis, and High-dimensionality

Shihao @ShihaoFeng18
27 Followers 131 Following
Sibabrata Biswal @Sibabrtwt
7 Followers 139 Following

Aniruddha Mukherjee @ani5692
189 Followers 385 Following Phd Candidate @UAB_GBS | Writer @PhDsofIndia | BS-MS alumni @iiserkol | he/him.
Wei-Tse Hsu @WeiTseHsu
349 Followers 728 Following Postdoc @BiochemOxford. PhD from @ShirtsGroupCU. Keen on compchem, deep learning & education. Rookie runner. Originally from Taiwan.

Vinay Prabhu 🧬+�... @vinayprabhu
2K Followers 485 Following 🎓={ EE @ IIT Madras, PhD @ Carnegie Mellon University} 📖={Information Theory, AI, Omics} Launching soon: 🏢= {{🐍,🕷️,🪼},🧬,🤖} x {🧪,💊,💉}
Young D. Kwon ✈️ ... @YoungDKwon1
409 Followers 1K Following AI Scientist @ Samsung AI | Shipped on-device GenAI to Galaxy flagships (S24 · S25 · S26) | Visiting Scholar & PhD @ Cambridge | ML & Systems Rising Star (2025)


AsyncAwait @SHRIKANTPADHY2
125 Followers 2K Following SDE2 Software Engineer || Ex @OptymLE, Ex @TIAA, Ex @oneture, Ex @TnaTanapp
Vinicius Reis @vfreis
31 Followers 749 Following



Sam Shrestha @SamShre1139089
10 Followers 676 Following
Tamera Oberbrunner @TameraObernyai
1 Followers 1K Following

Frederic Petrignani @eyano2184
2 Followers 564 Following
quantum @sudodaemonn
28 Followers 721 Following 22 | wannable AI "software engineer". skeptical about AI, engineering, philosophy. rest just still figuring out ig..

Georgia Channing @cgeorgiaw
6K Followers 423 Following AI4Science @ 🤗, PhD @OxfordTVG — science is a candle in the dark
Paul Kohlhaas bio/acc @paulkhls
28K Followers 4K Following building the scientific singularity / founder & ceo @bioprotocol @molecule_sci pioneering @peptai_ @vitadao / alum @Consensys @AfrikaBurn @HSGStgallen capri ♑️
Dr Aniruddha Malpani,... @malpani
91K Followers 8K Following Lifelong Learner. Angel Investor. Funding Frugal Innovation to Improve Indian Education. IVF Specialist. Anti-Corruption Activist. Patient Advocate.

Jason Kelly @jrkelly
33K Followers 3K Following Co-founder and CEO at Ginkgo Bioworks ($DNA)🧬 Former Chair of US National Security Commission on Emerging Biotechnology 🇺🇸
Jonah Kallenbach @jonahkallenbach
947 Followers 2K Following Researcher @anthropicai. Previously founder & CEO @reverielabs, AB/SM in CS from @hseas.
Vincent Weisser @vincentweisser
29K Followers 6K Following ceo @primeintellect — building self improving agents & infra
Cory Kornowicz @cory_jay44
696 Followers 559 Following RIT ‘22 B.S. Bioinformatics and Comp Biology. Developing next-generation drug discovery tools, co-founder/cso @try_litefold @theresidency @inventorsRes
Derya Unutmaz, MD @DeryaTR_
338K Followers 8K Following Professor scientist, immunologist, biomedical engineer & Biohacker. ALL IN ON AI ! #Longevity #BioAI #Codex #Robotics #Space #Scifi #Singularity #trekkie 🖖

Anindyadeep @anindyadeeps
3K Followers 1K Following Building Rosalind, Co-Founder @try_litefold, an AI Co-Scientist for therapeuticsYou might like



















