

-
Tweets813
-
Followers158
-
Following1K
-
Likes3

David Sacks really understands AI and cares about the US leading in innovation. I am grateful we have him.

INSIDE NYT’S HOAX FACTORY Five months ago, five New York Times reporters were dispatched to create a story about my supposed conflicts of interest working as the White House AI & Crypto Czar. Through a series of “fact checks” they revealed their accusations, which we debunked




It has been amazing to watch the progress of the Codex team; they are beasts. The product/model is already so good and will get much better; I believe they will create the best and most important product in the space, and enable so much downstream work.
A first preview of something we expect to see a lot more of soon:

3 years ago we could showcase AI's frontier w. a unicorn drawing. Today we do so w. AI outputs touching the scientific frontier: cdn.openai.com/pdf/4a25f921-e… Use the doc to judge for yourself the status of AI-aided science acceleration, and hopefully be inspired by a couple examples!

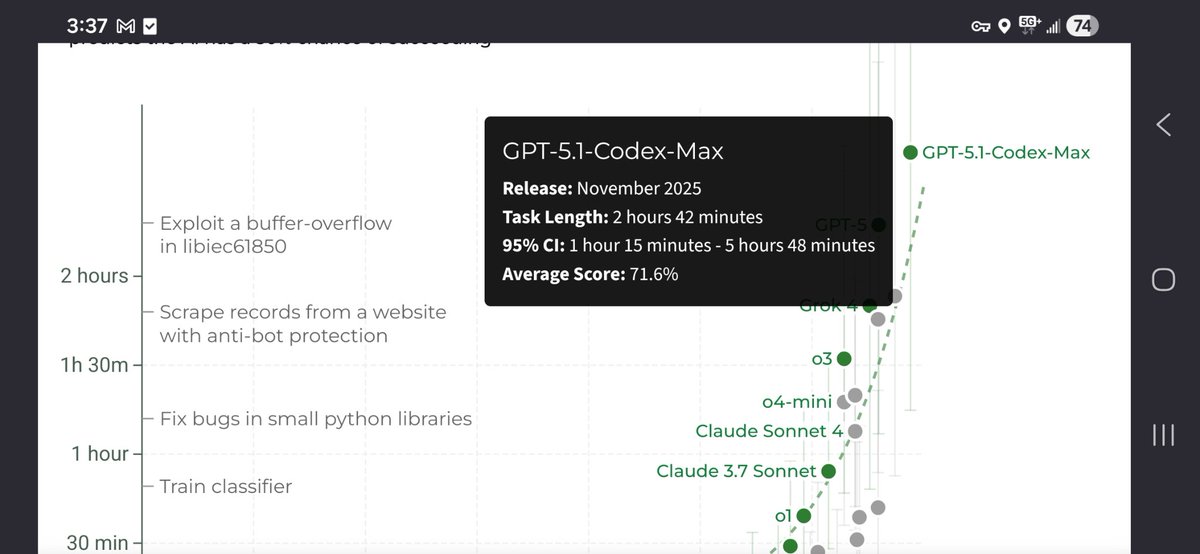
New Codex model is a significant improvement!

METR (50% accuracy): GPT-5.1-Codex-Max = 2 hours, 42 minutes This is 25 minutes longer than GPT-5.
Congrats to Google on Gemini 3! Looks like a great model.
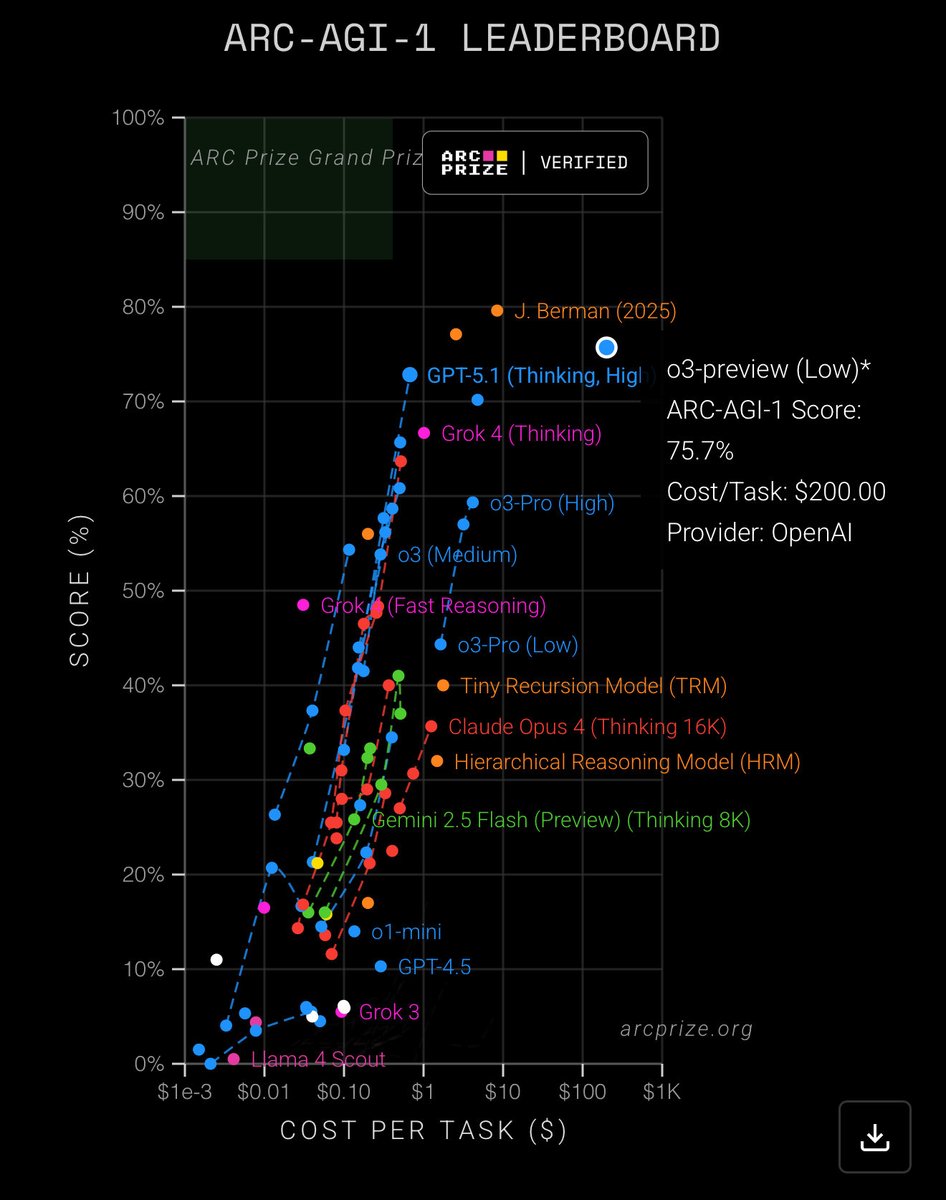
The rate reduction in price per unit of intelligence has been thing I've most consistently underestimated the past couple of years. 300x in a year is nuts!

GPT-5.1 (Thinking High) is about 300 times cheaper per task than o3-preview (Low) while scoring only a few points lower on ARC-AGI-1. 1 year later intelligence has gotten 300 times cheaper. This is why I can’t stand people who say “wahh the models too expensive” it will become

a new type of research company!

Today, we're announcing @episteme, a new type of R&D company that recruits exceptional scientists to pursue high-impact ideas. Science isn’t bottlenecked by the availability of talent, but by places where they can do their best work. Scientific progress has driven human
This is exciting; I expect we are going to see a lot more things like this and it will be one of the most important impacts of AI. Congrats to the Future House team. edisonscientific.com/articles/annou…
Small-but-happy win: If you tell ChatGPT not to use em-dashes in your custom instructions, it finally does what it's supposed to do!
GPT-5.1 is now available in the API. Pricing is the same as GPT-5. We are also releasing gpt-5.1-codex and gpt-5.1-codex-mini in the API, specialized for long-running coding tasks. Prompt caching now lasts up to 24 hours! Updated evals in our blog post.
Understanding neural networks through sparse circuits:

We’ve developed a new way to train small AI models with internal mechanisms that are easier for humans to understand. Language models like the ones behind ChatGPT have complex, sometimes surprising structures, and we don’t yet fully understand how they work. This approach

We’re fighting this overreach on user privacy. As @sama has mentioned before, we need a new form of privilege - AI privilege - given some of the kinds of conversations people are having with these tools today. Fittingly, Nils Gilman published an op-ed in the NYT discussing AI privilege just the other day. The conversation by conversation analysis necessary to provide that kind of respect highlights just how wild it is to ask for 20m conversations indiscriminately.
A letter from our CISO: "Fighting the New York Times’ invasion of user privacy" openai.com/index/fighting…
GPT-5.1 is out! It's a nice upgrade. I particularly like the improvements in instruction following, and the adaptive thinking. The intelligence and style improvements are good too.
Also, we've made it easier to customize ChatGPT. You can pick from presets (Default, Friendly, Efficient, Professional, Candid, or Quirky) or tune it yourself.

Welcome @sk7037 to OpenAI! Incredibly excited to work with him on designing and building our compute infrastructure, which will power our AGI research and scale its applications to benefit everyone.

This is an important one, I think. AI progress and recommendations: openai.com/index/ai-progr…
The government has played a role in critical infrastructure builds. Our public submission (posted on our blog) shares our thinking and suggests ideas for how the US government can support domestic supply chain/manufacturing. This is very in line with everything we have heard from the government about their priorities. We think US reindustrialization across the entire stack--fabs, turbines, transformers, steel, and much more--will help everyone in our industry, and other industries (including us). To the degree the government wants to do something to help ensure a domestic supply chain, great. This is part of a national policy that makes sense to me. But that's super different than loan guarantees to OpenAI, and we hope that's clear. It would be good for the whole country, many industries, and all players in those industries.

Some thoughts on the whole 'OpenAI loan guarantee" situation. 1. First, for context: this issue began a few days ago when openai CFO Sarah Friar publicly floated the idea of the federal government providing a loan guarantee for the development of ai data centers. 2. I, and
I would like to clarify a few things. First, the obvious one: we do not have or want government guarantees for OpenAI datacenters. We believe that governments should not pick winners or losers, and that taxpayers should not bail out companies that make bad business decisions or otherwise lose in the market. If one company fails, other companies will do good work. What we do think might make sense is governments building (and owning) their own AI infrastructure, but then the upside of that should flow to the government as well. We can imagine a world where governments decide to offtake a lot of computing power and get to decide how to use it, and it may make sense to provide lower cost of capital to do so. Building a strategic national reserve of computing power makes a lot of sense. But this should be for the government’s benefit, not the benefit of private companies. The one area where we have discussed loan guarantees is as part of supporting the buildout of semiconductor fabs in the US, where we and other companies have responded to the government’s call and where we would be happy to help (though we did not formally apply). The basic idea there has been ensuring that the sourcing of the chip supply chain is as American as possible in order to bring jobs and industrialization back to the US, and to enhance the strategic position of the US with an independent supply chain, for the benefit of all American companies. This is of course different from governments guaranteeing private-benefit datacenter buildouts. There are at least 3 “questions behind the question” here that are understandably causing concern. First, “How is OpenAI going to pay for all this infrastructure it is signing up for?” We expect to end this year above $20 billion in annualized revenue run rate and grow to hundreds of billion by 2030. We are looking at commitments of about $1.4 trillion over the next 8 years. Obviously this requires continued revenue growth, and each doubling is a lot of work! But we are feeling good about our prospects there; we are quite excited about our upcoming enterprise offering for example, and there are categories like new consumer devices and robotics that we also expect to be very significant. But there are also new categories we have a hard time putting specifics on like AI that can do scientific discovery, which we will touch on later. We are also looking at ways to more directly sell compute capacity to other companies (and people); we are pretty sure the world is going to need a lot of “AI cloud”, and we are excited to offer this. We may also raise more equity or debt capital in the future. But everything we currently see suggests that the world is going to need a great deal more computing power than what we are already planning for. Second, “Is OpenAI trying to become too big to fail, and should the government pick winners and losers?” Our answer on this is an unequivocal no. If we screw up and can’t fix it, we should fail, and other companies will continue on doing good work and servicing customers. That’s how capitalism works and the ecosystem and economy would be fine. We plan to be a wildly successful company, but if we get it wrong, that’s on us. Our CFO talked about government financing yesterday, and then later clarified her point underscoring that she could have phrased things more clearly. As mentioned above, we think that the US government should have a national strategy for its own AI infrastructure. Tyler Cowen asked me a few weeks ago about the federal government becoming the insurer of last resort for AI, in the sense of risks (like nuclear power) not about overbuild. I said “I do think the government ends up as the insurer of last resort, but I think I mean that in a different way than you mean that, and I don’t expect them to actually be writing the policies in the way that maybe they do for nuclear”. Again, this was in a totally different context than datacenter buildout, and not about bailing out a company. What we were talking about is something going catastrophically wrong—say, a rogue actor using an AI to coordinate a large-scale cyberattack that disrupts critical infrastructure—and how intentional misuse of AI could cause harm at a scale that only the government could deal with. I do not think the government should be writing insurance policies for AI companies. Third, “Why do you need to spend so much now, instead of growing more slowly?”. We are trying to build the infrastructure for a future economy powered by AI, and given everything we see on the horizon in our research program, this is the time to invest to be really scaling up our technology. Massive infrastructure projects take quite awhile to build, so we have to start now. Based on the trends we are seeing of how people are using AI and how much of it they would like to use, we believe the risk to OpenAI of not having enough computing power is more significant and more likely than the risk of having too much. Even today, we and others have to rate limit our products and not offer new features and models because we face such a severe compute constraint. In a world where AI can make important scientific breakthroughs but at the cost of tremendous amounts of computing power, we want to be ready to meet that moment. And we no longer think it’s in the distant future. Our mission requires us to do what we can to not wait many more years to apply AI to hard problems, like contributing to curing deadly diseases, and to bring the benefits of AGI to people as soon as possible. Also, we want a world of abundant and cheap AI. We expect massive demand for this technology, and for it to improve people’s lives in many ways. It is a great privilege to get to be in the arena, and to have the conviction to take a run at building infrastructure at such scale for something so important. This is the bet we are making, and given our vantage point, we feel good about it. But we of course could be wrong, and the market—not the government—will deal with it if we are.
A thing often in common among great startup investors, founders, and researchers: Trading making a lot of small mistakes in exchange for getting a few giant wins. (Surprisingly many people seem to prefer a few big mistakes in exchange for a lot of small wins.)
interesting post from @boazbaraktcs: windowsontheory.org/2025/11/04/tho…

Aleksandr @AlexSabirov1
0 Followers 25 Following
Peter Kang @PeterKang2017
0 Followers 148 Following
megaf megaf @megaf0914
1 Followers 13 Following
Ben @Ben162882542376
1 Followers 25 Following
weijin zeng @weijinzeng
0 Followers 3 Following
Adrian Neizer Aboagye @djneizer
2K Followers 1K Following 🎧 DJ Neizer @Acenightclub Telecom Expert | Data Scientist | Entrepreneur Music • Tech • Culture
Human Nodes @humannodes2206
2 Followers 38 Following Mapping the unmapped. Human nodes connecting in the age of AI. The map doesn't exist yet.
KarinK @KKlerby
80 Followers 425 Following All about sustainable development, human rights, gender equality, democracy, nature, art & food. Currently residing in Monrovia, Liberia. Retweet ≠ endorsement
Soham @Soham1552479
0 Followers 15 Following
John @jesponaug
17 Followers 261 Following
Marnon @marnon00
221 Followers 235 Following
Wenze Li @WenzeLiqi
0 Followers 22 Following
CURIOUS_CORNERS @curiouscorners
1K Followers 1K Following 長野出身、ボストンで大学を出てNYで野生化しました。紺屋と画商をやってます。 / 🚴♀️🚲🐈🐈⬛/ #マヌルの民
Jiahong Chen @JiahongCheqltk
1 Followers 6 Following
Prateek Kumar Arya @PrateekKum64268
4 Followers 215 Following
Tom Judd @ImTomJudd
0 Followers 27 Following
isacco @isxccs
0 Followers 5 Following
Zeeshan Ali @zesnai
10 Followers 91 Following
David @Ace_Swearengen
205 Followers 1K Following
Desdemona @Segundo529612
23 Followers 939 Following Confidence is not “they will like me.” Confidence is “I’ll be fine if they don’t.”
Zain Merchant @ZainMerchant10
4 Followers 58 Following
Arty @Arty829
0 Followers 256 Following
Kelly Kiser @rationabile28
1 Followers 46 Following
L S @LS3551015573992
1 Followers 20 Following
Jamal & Alia Arianna ... @ari_alia34927
0 Followers 35 Following
Hackrest @hackrest_
3 Followers 27 Following AI-Powered Automation & Digital Solutions AI Calling Agents • Chatbots • Software Helping businesses scale smarter
Abdalla Eltom @AbdallEltom
14 Followers 789 Following
Camila Camargo Malta @CamilaaMalta
7 Followers 66 Following


Sunil Sharma🇮🇳 @sunieljkb
61 Followers 452 Following सर्वे भवन्तु सुखिन: सर्वे सन्तु निरामया: सर्वे भद्राणि पश्यन्तु मा कश्चिद् दु:ख भाग्भवेत् ॥

Sigrid @ArchibaldA36263
221 Followers 7K Following

🧉 @7l7l1l
266 Followers 2K Following
Eduardo DoSantos @dosantitos
4K Followers 161 Following El Daddy para tus issues 😅 bebé 🙃 Sígueme para ser novios😍
Robert Dorr @Bob_Dorr_2020
570 Followers 3K Following Team member at Americans for Safe Aerospace, https://t.co/K4dGw3Fj4I. Also on Flipboard: GNC | Global News Curator https://t.co/99gGniBLkD
Stephanie @Strepahiwnpeter
510 Followers 2K Following I’m Stephanie , the wife of Dirty Tesla providing you with behind the scenes monuments and also the personal manager of Elon musk

Puiiemiex @Puiiemiex75898
30 Followers 1K Following
Kisha @ashontiwats44
64 Followers 3K Following
QualityStocks🇺🇸 @Miexdor46861
42 Followers 2K Following 15-30% Monthly | 2 High-Conviction Stocks.Short-Term Gains: 15-20% in Days/Weeks.DM "JOIN" for WhatsApp Alerts. Live Trade Signals • Market Analysis
DeltaDivergence🇺�... @Wedear0047
41 Followers 2K Following 15-30% Monthly | 2 High-Conviction Stocks.Short-Term Gains: 15-20% in Days/Weeks.DM "JOIN" for WhatsApp Alerts. Live Trade Signals • Market Analysis
Colt Zieme @ColtZieme84741
131 Followers 5K Following
Vlirota @Vlirota9779056
0 Followers 40 Following
Huisieh @Huisieh286
45 Followers 2K Following
She Nanigans @Lorelei69
2K Followers 3K Following Holds grudges for 3-5 business days/Eco-Unfriendly/High-maintenance & low-tolerance/Anti-Empath/crisis actress/Certified Last Responder/72 countries/Soulless
Jennifer @Cago989173
1 Followers 105 Following Bravely pursue value, handle risks with caution, go further on the investment journey. — Raymond Lillda
Robin O'Hara @RobinOHara52817
1K Followers 2K Following
Diane Wood @Wood141939Diane
963 Followers 2K Following Business owner, and MAGA supporter, I love dogs, sailing, and wine tasting. I believe Donald Trump is entitled to a do-over!!!
pascale SEBILLE @pascaleSEBILLE
5 Followers 67 Following
james @laviris_lee
42 Followers 220 Following
Marnon @marnon00
221 Followers 235 Following
Diego Tamayo @murdie24
2 Followers 26 Following
Sajish Jose @JoseSajish
14 Followers 72 Following
Rafael @rafaelmomberg
44 Followers 83 Following Business, tech, and taste. Data & Ops @ Xeneta | Operating Partner @ https://t.co/eGY8l4Xges ex @Odoo, @Polimi, @USPonline Shipping: https://t.co/KqdaMcFa4i
The Trusted Hand @TheTrustedHand
27 Followers 121 Following Wish others well. Their success will not limit yours.


Ry F @JyotiRyan21
28 Followers 258 Following
なかむらべーす @muranonakano
535 Followers 990 Following コーヒー焙煎、始めました!アイアンマンになりたい。筋トレと英語とpythonと株の運用を極めます! 相手をRespectし、感謝を伝え、生活の中に散りばめられた幸せを奇跡と捉え、邁進してゆきます!
Bogdan @b_deleanu
87 Followers 562 Following Romanian, East European, EU true believer, prefers science and good fantasy books to imaginary friends in the sky and men with weird hats.
Prateek Kumar Arya @PrateekKum64268
4 Followers 215 Following
Kevin E. Files @kevinefiles
209 Followers 360 Following With the state of agentic engineering and how fast the space changes - what do you even build?


Jim Fan @DrJimFan
470K Followers 3K Following NVIDIA Director of Robotics & Distinguished Scientist. Co-Lead of GEAR lab. Solving Physical AGI, one motor at a time. Stanford Ph.D. OpenAI's 1st intern.
Eliezer Yudkowsky ⏹... @ESYudkowsky
229K Followers 101 Following The original AI alignment person. Understanding the reasons it's difficult since 2003. This is my serious low-volume account. Follow @allTheYud for the rest.
VERIC CORP @vericcorp
34 Followers 49 Following
Luke Hutchison @LukeHutchison
386 Followers 1K Following Founder/CEO @perfectvenueco - we help restaurants win in the 21st century 🍔
Torben Mark Pedersen @torbenmarkp
6K Followers 1K Following Ph.D, in economics. University of Copenhagen, Harvard University and University of Chicago. Libertarian. Editor of Libertas 🇩🇰🗽📚🍒🥂
Ghanshyam Patel @ghanshyamrpatel
128 Followers 468 Following
George McDougall @camerondtaylor
34 Followers 225 Following
Karissa Paddie @karissapaddie
1K Followers 1K Following Head of Startups @deel. Founder @growthmarketrs. Ex-philosophy.
TJF @TomFinn79862654
142 Followers 932 Following
Dan DeVries @danieljdevries
6K Followers 7K Following President & COO #Ecommerce @decomarche #Marketing #Sales #Startups #Operations #Socialmedia #CX #Tech #EmergingTech #AI #Marketplace

heather @3mchess3
2K Followers 2K Following Proud to be a hard-working AMERICAN 🇺🇸🇺🇸🇺🇲🇺🇲 No Surrender! Carnivore.
Strebl Steve @SteveStrebl
85 Followers 265 Following Cutting through 🇪🇺🇬🇧 red tape from 🇺🇸 | Vegan (yes, Vegas) | Helping small businesses beat absurd regulation | Western values, Wild West mindset
Pritam Jamdade @iampritamj
473 Followers 164 Following Building a $1M solo AI company | 10 years of Marketing Experience | Vibe Coder 🚀
🌏Sander van Liempd... @sander496
433 Followers 273 Following Exploring foundational questions in physics, health & human nature. Developing the Relational Gradient philosophy.
alest.io @fernandoce4919
236 Followers 533 Following
Alexander Kay @AltCoinAnimal
61 Followers 140 Following
Ayhan Kamil @ayhankamil
140 Followers 1K Following Chief Operating Officer & Cofounder @ AstraUTM - A Thales Company, #UTM #AAM #UAM #USpace : building the future of airspace management!
Dennis Voznesenski @Voz_Dennis
4K Followers 1K Following Agricultural economist at CBA and author of “War and wheat,” available now on Amazon

Misha Jurin @mishajurin
566 Followers 139 Following building @QANplatform | in crypto trenches since 2017 | posts reflect my personal views | not financial advice


Jason Lee @JasonLeeUT
241 Followers 301 Following
Daniel Leon @dmleon10
432 Followers 482 Following Co-Founder @AkaveCloud @akavenetwork, data layer for enterprise & AI | Filecoin Ecosystem | visit https://t.co/PJ2HMfjEGf
Vinicius Rocha @vmrocha
298 Followers 372 Following


Raphael Césari @rafaminos
280 Followers 294 Following Macro Strategist at Les Cahiers verts de l'Economie, (amateur) epidemiologist, (amateur) supply chain manager
Igor Trunov @i_trunov
104 Followers 171 Following Founder&CEO of Ventora. Member of @forbes_councils An entrepreneur is a dreamer who has a plan
Keegan McBride @KeeganMcB
2K Followers 2K Following Views are my own. RTs ≠ Endorsements. Director for Science and Tech @ Tony Blair Institute
Ryan Franklin @ryfranklin
89 Followers 434 Following Data Architect & Engineering Consultant | ASU Alumni 🔱
Terry Grosenheider @terrywg1
279 Followers 909 Following Family, photography, skiing, not so much running anymore
Aidan Boran @aidan_boran
539 Followers 707 Following Founder/CEO at Digital Gait Labs. Making clinical gait analysis as easy as taking a patient’s temperature. GaitKeeper is a CE marked, Class 1 medical device.Trends for United States
You might like



















