
main @main_horse
AGI Believer. Haven't applied @OpenAI. Likes are not always endorsement. main.horse Joined December 2022-
Tweets3K
-
Followers8K
-
Following457
-
Likes27K
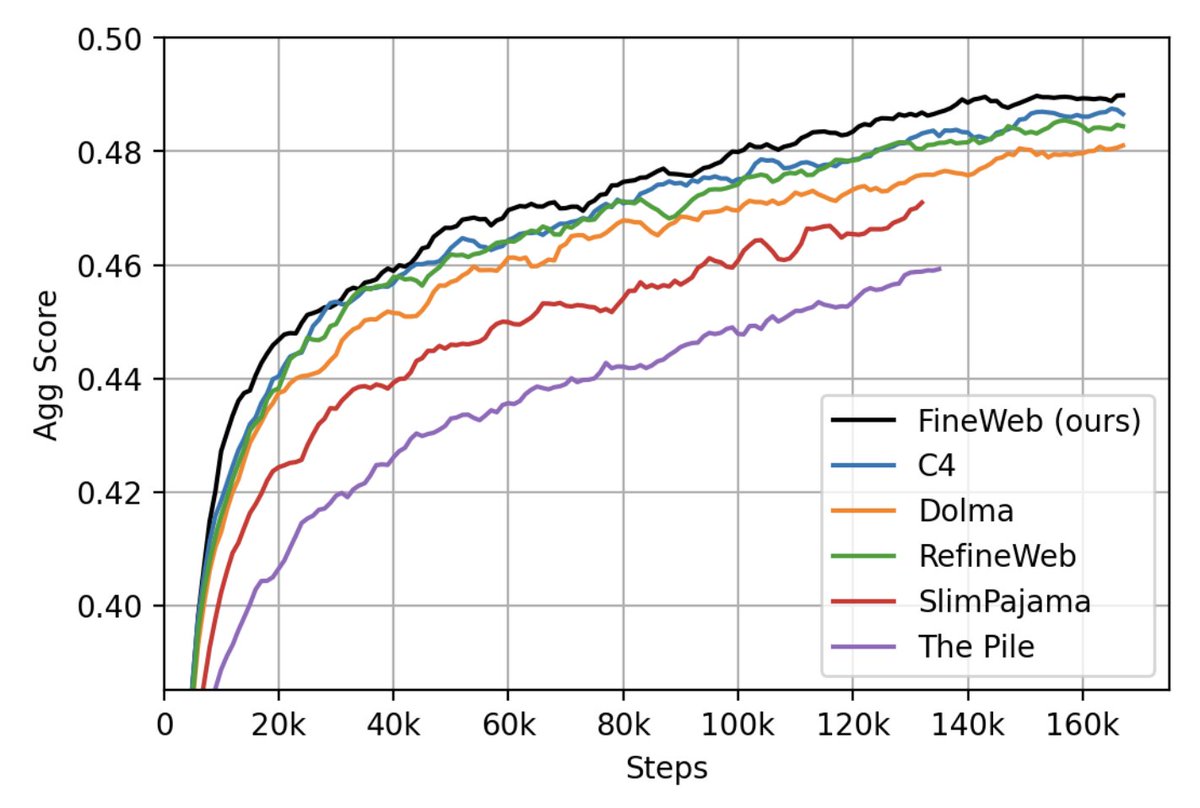
We have just released 🍷 FineWeb: 15 trillion tokens of high quality web data. We filtered and deduplicated all CommonCrawl between 2013 and 2024. Models trained on FineWeb outperform RefinedWeb, C4, DolmaV1.6, The Pile and SlimPajama!

Zuck on: - Llama 3 - open sourcing towards AGI - custom silicon, synthetic data, & energy constraints on scaling - Caeser Augustus, intelligence explosion, bioweapons, $10b models, & much more Enjoy! Links below

LLAMA-3 IS OUT! llama.meta.com/llama3/


what if u could watch anime AND design distributed systems at the SAME TIME we're drowning in gpus and need a giga cracked systems engineer asap dm @ok_ikaros w/ name of best waifu/husbando, along with ur hottest take: like how nomad mogs k8s, or how scylladb sucks tokyo/sf


🎨Spent some time refactoring the 2021 post on diffusion model with new content: lilianweng.github.io/posts/2021-07-… ⬇️ ⬇️ ⬇️ 🎬Then another short piece on diffusion video models: lilianweng.github.io/posts/2024-04-… (Yes, I had an intensive weekend🥹)
powerful energy in this note


powerful energy in this note https://t.co/2hdwC9ZlUJ



Proposal: with new MoEs, let's discuss less about the total number of experts, and instead focus on the two main things that we care about: - # of total params - # of default activated params Mixtral-8x7B -> Mixtral-47B-A12B Mixtral-8x22B -> Mixtral-141B-A35B

Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic Argues that data curation cannot be agnostic of the total compute that a model will be trained for repo: github.com/locuslab/scali… abs: arxiv.org/abs/2404.07177
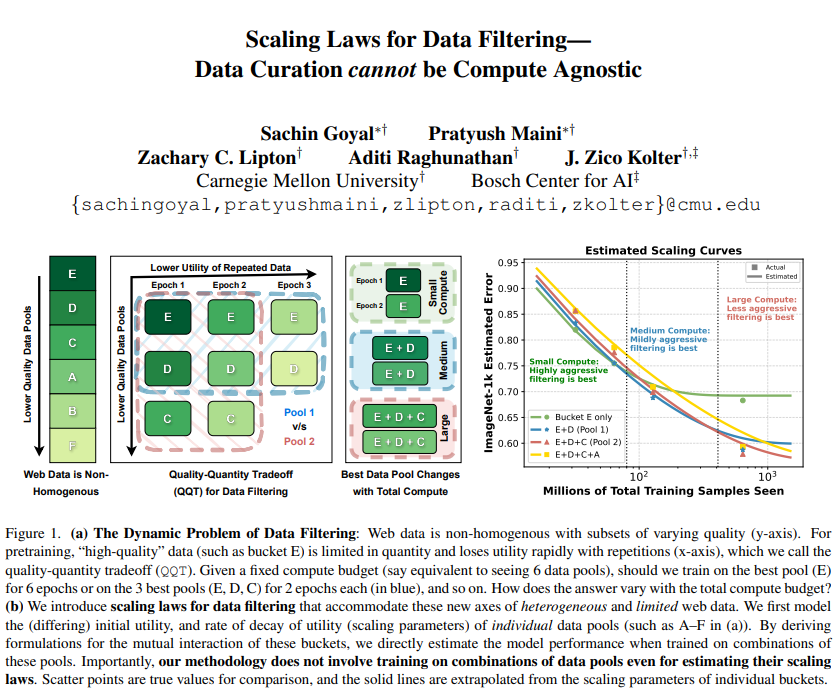
Our 12 scaling laws (for LLM knowledge capacity) are out: arxiv.org/abs/2404.05405. Took me 4mos to submit 50,000 jobs; took Meta 1mo for legal review; FAIR sponsored 4,200,000 GPU hrs. Hope this is a new direction to study scaling laws + help practitioners make informed decisions


I do hope that BitNet [works at scale and] is broadly compatible But which sparsity methods are stackable between themselves, and when do they tap into the same redundancies? We'll see the attempt at ReLUfied Mixtral soon. And it seems that GQA already competes with ReLUfication.



I do hope that BitNet [works at scale and] is broadly compatible But which sparsity methods are stackable between themselves, and when do they tap into the same redundancies? We'll see the attempt at ReLUfied Mixtral soon. And it seems that GQA already competes with ReLUfication. https://t.co/1WYf2itxJ2

@dwarkesh_sp @_sholtodouglas @LukeFarritor I'll pledge $25k in prize money to this if it becomes an actual contest
some smaller targets worth taking iff too GPU poor to analyze mixtral: qwen1.5-moe (upcycled!) qwenlm.github.io/blog/qwen-moe/ deepseek-moe github.com/deepseek-ai/De… openmoe-8b github.com/XueFuzhao/Open… switch-base-8 huggingface.co/google/switch-…
some smaller targets worth taking iff too GPU poor to analyze mixtral: qwen1.5-moe (upcycled!) qwenlm.github.io/blog/qwen-moe/ deepseek-moe github.com/deepseek-ai/De… openmoe-8b github.com/XueFuzhao/Open… switch-base-8 huggingface.co/google/switch-…
Had so much fun chatting with my friends @TrentonBricken and @_sholtodouglas. No way to summarize it, except: This is the best context dump out there on how LLMs are trained, what capabilities they're likely to soon have, and what exactly is going on inside them. You would be…

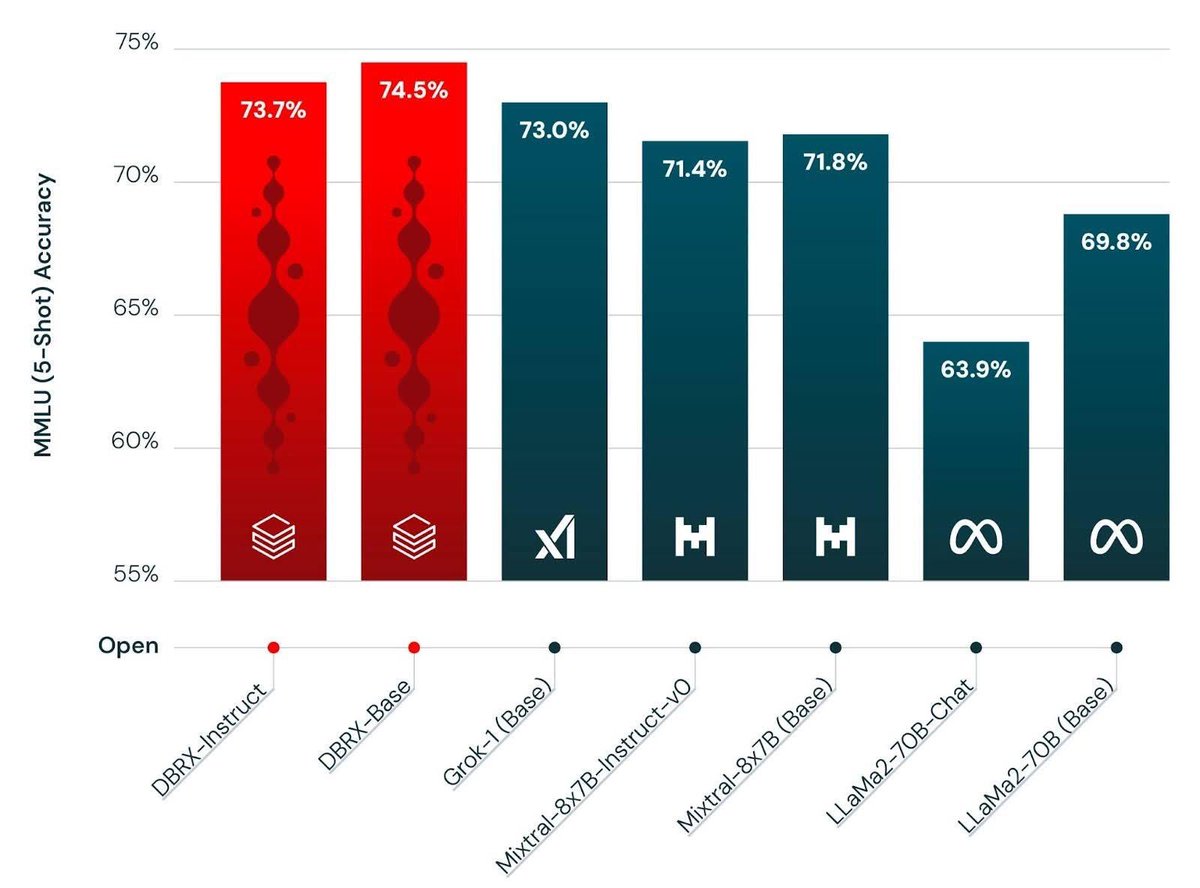
It’s finally here 🎉🥳 In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context length and trained for 12T tokens 🤯

You have all been very patient, so here you go. 7x4090 Writeup. And don't you dare shame my frontend skills. mov-axbx.com/wopr/wopr_conc… Now go buy some GPUs and get to it.

ping us if you both identity with sen, and also aspire to train real foundational model instead of just wrapping gpt4/claude I think we comfortably have 10-100x more compute than anyone else in the anime industry

ping us if you both identity with sen, and also aspire to train real foundational model instead of just wrapping gpt4/claude I think we comfortably have 10-100x more compute than anyone else in the anime industry


Trect @trectadactyl0
18 Followers 147 Following alt | AI founder | stats, ML & finance | ex. Jane skreet, ex google | milady world order
CrypticAbsolon @CrypticAbsolon
6 Followers 41 Following

Ma Sheen @MaSheenUprising
8 Followers 998 Following “The programme will take me a little while to run.” Fook glanced impatiently at his watch.
Stefan Juang @StefanJuang
146 Followers 1K Following The final goal of AI is not just to create intelligent machines, but to understand intelligence itself.
Alessandro Scarcella @__alesca__
136 Followers 929 Following ML engineer. Free banking. I invoke my right to change my opinion
Nicholas Kross (pause.. @NicholasKross
189 Followers 776 Following Barreling (slowly ;-;) headfirst into AI alignment research. By day, software test engineer.
Robert Skopal @skopal_robert
3K Followers 6K Following Libertarian,free thinker.Spirituality,science,tech,investing,philosophy,history,politics.
KeepItRealness @KeepItRealness
55 Followers 792 Following
MMM @MMM1897775
9 Followers 806 Following
camhowe @camhowe1729
4 Followers 216 Following full-time techbro, part-time anon/undergrad. love explaining tech stuff.

Fernando Peña @ElBuenFercho
11 Followers 345 Following

Lee @LeeMarie222
2K Followers 6K Following Prize winning poet, lover of biology, the study of medicine, art, dance, cosmology, geology, anthropology, music & languages. Follow me!
wqhff @wqhff3
29 Followers 85 Following
Ahmed Hisham @AhmedHi08078280
0 Followers 50 Following
NekoKazama @kazama_do
122 Followers 1K Following


Anton Ermolov @TwanErms
98 Followers 317 Following Not all those who wander are lost. Passionate about all things travel, history, fitness, art, hiking, and technology. Investor @ GBV
Dana Mahmood @deordered
22 Followers 720 Following Fine-tuning AI models oftentimes & practicing philosopher at other times.
pamara andarion🧝�.. @thealienpam
151 Followers 636 Following alien pam 👽 | cyber-venetian emissary 💌 | my ufo wrapped in swarovski crystals girl 🪩🛸
Mahaoo @mahaoo_ASI
18 Followers 177 Following unhinged socially unacceptable takes about humanity and ASI
Xilo @PandoXiloscient
453 Followers 576 Following The future belongs to benevolent zaibatsu | Increasing global energy consumption | e/λ


Ami yousef @Amiyousi
74 Followers 385 Following

max @m_a_x_p_n
1 Followers 94 Following
Dolph. @dolphinboywazzz
21 Followers 1K Following

123wazzino @xiji123
325 Followers 4K Following
autonomous noumena no.. @microsoft_worm
503 Followers 3K Following I am what I am • she/her • Discord: `parenthetically`
Sameer Ahmed @SameerA41115539
665 Followers 5K Following M2 Interested in Evolutionary Medicine, History of Medicine and Science, and Public Health
Levi Githaiga @CodeTitanium
11 Followers 384 Following
AIBabysteps @AiBabysteps
6 Followers 153 Following
fabian fronhofer @fabianfronhofer
629 Followers 5K Following Intrapreneur | AI Operations Expert | Digital Marketing | Digital Products | Digital Transformation // Impressum/Datenschutz: https://t.co/l9LWBOv3V5

ยิรา @1D80gDNDqNhhC1
52 Followers 1K Following เป็นเกียรติอย่างยิ่งที่ได้พบคุณที่นี่ หากชอบ ติดตามได้ ผมจะอัพเดตข้อมูลติดต่อในหน้าแรกได้ตลอดเวลาครับ
emi learns @ml_emiii
7 Followers 101 Following learning llm engineering and advanced/concurrent typescript/js from ground up before @elicitorg internship
Yorick van Zweeden @YorickZweeden
5 Followers 46 Following
Jatin Nainani Z 🍃 @zephyr_wade
57 Followers 391 Following Trying to reverse engineer intelligence @ Umass CS
Samir @samir_moussa
345 Followers 2K Following ML engineer @usecaribou (YC W19). Prev data scientist @signalhq
Priyav K Kaneria @_diginova
69 Followers 381 Following Adapting is underrated. time spent with me is an investment. assume that i have an anime pfp
Sam Coward @samcoward
387 Followers 1K Following Father, husband, subpar musician. Platform Engineering @VMWare Tanzu. XP, Agile. Leveling up on AI and ML; accelerating.
Garrett -DeepWriterAI @DeepAIWriter
12K Followers 6K Following Over-engineering Agentic Systems for long-form writing. Generating scripts, fiction or non, breakthrough ideas, whole universes, etc. The Deep Writer. DM4demo.
Victoriayiyiyi @jnwangyi
128 Followers 2K Following

Pytorch To Atoms @PytorchToAtoms
10 Followers 18 Following Deep Dive Across the Whole Stack from Pytorch to Cuda To Atoms
virat @virattt
6K Followers 77 Following Exploring multimodal AI models and sharing what I learn along the way • previously @AirbnbEng
Alan Lockett @hypernicon
47 Followers 116 Following
sankalp @dejavucoder
6K Followers 510 Following 5x engineer, natural agi. mostly shitposting, occasionally insightful. chai, anime and ai enjoyer. leveling up in llm landscape
Senthooran Rajamanoha.. @sen_r
100 Followers 43 Following

Nintendo .DS_Store @sliminality
10K Followers 177 Following I want to talk to you about the affect and aesthetics of computing. All my PLposting now lives at @[email protected]
Kenneth Li @ke_li_2021
714 Followers 418 Following
Yossi Kreinin @YossiKreinin
1K Followers 25 Following Animation: https://t.co/szZQmzdUUR Programming: https://t.co/WWRLYifnxh
Kevin Slagle @kjslag
95 Followers 193 Following professor @RiceUniversity interested in quantum physics and deep learning
Brian Huang @brianryhuang
1K Followers 1K Following





pleias @pleiasfr
236 Followers 1 Following
Rasmus Larsen @synquid
43 Followers 67 Following AI & LLMs @ Alexandra Institute. https://t.co/abXrErO7j3
Tomasz Kolinko @kolinko
3K Followers 545 Following Effort - https://t.co/ScM4oPI5JG - an llm inference algorithm , previously https://t.co/MHsV9jJryz - decompiler for Ethereum smart contracts.

efxmarty @efxmarty
343 Followers 134 Following ML Engineer at @huggingface Optimization team. efxmarty/fxmarty elsewhere
ikaros / イカロス @ok_ikaros
350 Followers 170 Following product @spellbrush @nijijourney | edelgard simp

Sergey Levine @svlevine
80K Followers 122 Following Associate Professor at UC Berkeley Co-founder, Physical Intelligence
Yaroslav Ganin @yaroslav_ganin
4K Followers 231 Following Co-Founder @udiomusic. Research Scientist. Previously: @DeepMindAI, Mila (Montréal, Canada), Skoltech (Moscow, Russia). Views are my own.

David Ding @DavidDingAI
2K Followers 122 Following CEO and co-founder of @udiomusic. ex Google DeepMind
swyxio (mamba mode) @swyxio
1K Followers 1K Following @swyx’s waluigi. people praise you in public for the work you do in private.
Abhik Roychoudhury @AbhikRoychoudh1
1K Followers 57 Following Professor of Computer Science at National University of Singapore
udio @udiomusic
28K Followers 0 Following
Alexander Koch @alexkoch_ai
5K Followers 203 Following Founder of Tau Robotics (@taurobots) | Z Fellow | Emergent Ventures Fellow 2024
Zeyuan Allen-Zhu @ZeyuanAllenZhu
8K Followers 273 Following physics of language models @ Meta / FAIR IOI - USACO - MCM - ACM/ICPC - Codejam Tsinghua - MIT - Princeton/IAS - MSR - FAIR

Jerry Tworek @MillionInt
7K Followers 282 Following I teach programs how to program @ OpenAI | putting the ball in the damn hoop - @jacobmenick

dreadnode @dreadnode
783 Followers 22 Following AI Red Teaming | Research. Tooling. Evals. Cyber ranges.

Zellic @zellic_io
12K Followers 14 Following Security reviews and research that keep winners winning. We apply unmatched hacking talent to secure critical software for the most innovative teams.
Eric Steinberger @EricSteinb
7K Followers 478 Following Writing code that writes code on a mission to build safe superintelligence | CEO/cofounder @magicailabs

AI Safety Institute @AISafetyInst
541 Followers 29 Following We’re building a team of world leading talent to tackle some of the biggest challenges in AI safety - come and join us.
vLLM @vllm_project
778 Followers 11 Following A high-throughput and memory-efficient inference and serving engine for LLMs
Desh Raj @rdesh26
3K Followers 2K Following Research Scientist @Meta (AI Speech) | Previously: @jhuclsp, @IITGuwahati
Tristan Hume @trishume
6K Followers 330 Following Performance optimization lead @AnthropicAI. Profiling, distributed systems, dev tools, interpretability. [email protected]

Joseph Bloom @JBloomAus
186 Followers 148 Following Independent Alignment Research Engineer. Likes vegan food. loves puns.
Callum McDougall @calsmcdougall
276 Followers 4 Following AI safety researcher & fieldbuilder / film enjoyer / coffee drinker / Hitchhikers' Guide enthusiast.
bilal2vec @bilaltwovec
2K Followers 780 Following ✨ research engineer • prev @googlebrain @cohere @dbrxmosaicai • se @uwaterloo


ChatGPT told me this was the case a few months ago and I didn’t believe it 😂

Many don't know that GPUs automatically leverage ternary and fine-grained sparsity to accelerate your matmuls! e.g. A matmul with ternary + 90% sparsity results in 33% more FLOPs in my benchmark. (not joking) I explore this "optimization" here: thonking.ai/p/strangely-ma… (1/3)

mfw if that gpt2 thing comes out to be gpt4.5. i hope it is some different architecture or some old model trained with new techniques and more data.


@teortaxesTex Bloom is the worse model normalised by swe/researcher hours perhaps. Can't go lower than that. It's the absolute lower bound.
@agihippo Scared to ask what you think about BLOOM lol
15 people? That's cute. 😬 At reka our pretraining team is 3-5 people at max, who were all also working >50% time in other projects. 🫠

Our latest model Inflection-2.5 (inflection.ai/inflection-2-5) is not bad. In fact, it was the ~4th best publicly "known" models when it was released in early March. And it was created by our pretraining team of < 15 people! 2/
Boring paper/experiment idea: Scaling Laws for Distillation into Ternary Transformers (h/t @kalomaze for inspiration and the correct warning it's unlikely to work at proposed scale. Well, one could go bigger now) The objective: finding a compute-optimal regime to convert…
Tired but true lesson: small teams are more agile because they *don't need to* carry the weight of corporate politics. This can more than compensate for having fewer heads to bash at real problems. Case in point: BLOOM. I think Yi doesn't even have a separate "scaling team".

15 people? That's cute. 😬 At reka our pretraining team is 3-5 people at max, who were all also working >50% time in other projects. 🫠

realizing uni is almost over, and I still haven't figured out anything


@AdamSJermyn > fixing the values of other hyper parameters (learning rate, batch size, optimization protocol, etc.) why did you hold lr fixed when scaling? intuitively we'd expect larger autoencoders to require smaller lr, right? so this seems like a potential confounder

said he was “surprised i was a real person and in SF” although at least one of these is disclosed on my profile i wished him good luck. he was wearing a humane ai pin so i figured he’d need it
@nearcyan not that many people walk around wearing a Jensen electoral map cape
someone just randomly walked up to me to tell me he’s shorting nvidia. no clue how he knew what i looked like

YouTube is a ticket to the extraordinary One (really good) video turned Harvard student Wesley Wang into the youngest director in history to set up a movie at a major studio

I’d go so far as to say a 20ga would be enough, reducing payload requirements some. Hope they aren’t trying box mag though, very hard to tune the feed. Better off with tube fed or even a composite / 7075 Al revolver cylinder, chamber pressures are relatively low
Seriously, what took them so long to do this? #4 birdshot from an x-full choke will rip the crap out of anything unarmored, and at altitude poses no real threat to people and stuff on the ground

drone on drone violence is out of hand

The productivity hack of just being around highly intelligent / competent people is just so good, acts as a powerful forcing function to elevate your own game. And this obviously includes a romantic partner.

Sensetime's SenseNova 5.0 left great impression of investors. Stock doubled since release on 23rd Various AI benchmarks put SenseNova 5.0 broadly on same ballpark as GPT-4 Turbo, even better in some areas. Same w/ OpenCompass 2.0 It was trained on 10TB of token w/ 600B params…





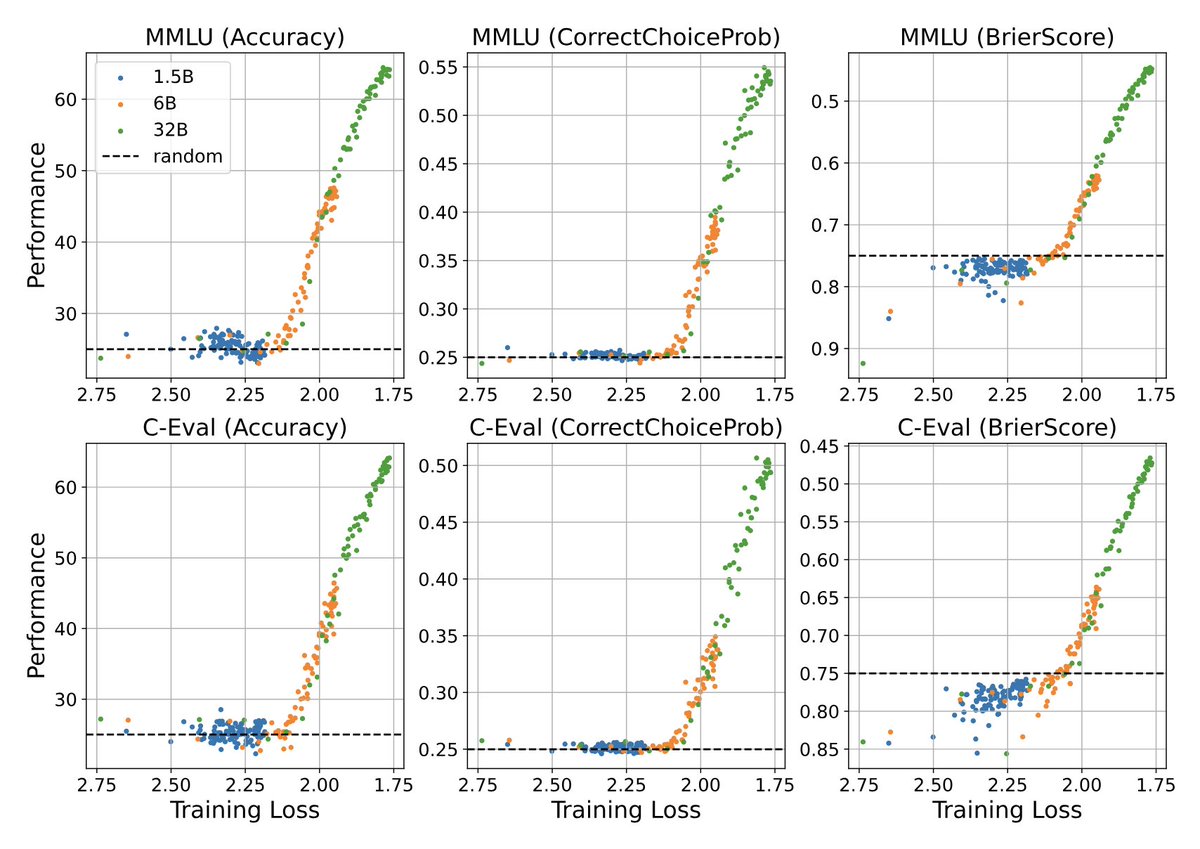
Enjoyed this paper that plots emergent abilities with pretraining loss on the x-axis, which is actually a suggestion that @OriolVinyalsML also made a few years back: arxiv.org/abs/2403.15796 The paper uses intermediate checkpoints to plot a variety of pretraining losses. For some…
SenseNova 5 is allegedly the best model they have now Roughly L3-405B compute-wise (if dense) x.com/tphuang/status…
Sensetime's SenseNova 5.0 left great impression of investors. Stock doubled since release on 23rd Various AI benchmarks put SenseNova 5.0 broadly on same ballpark as GPT-4 Turbo, even better in some areas. Same w/ OpenCompass 2.0 It was trained on 10TB of token w/ 600B params…
> In the first experiment, we train three models with 1.5B, 6B, and 32B parameters and observe their behaviors until trained on 3T, 3T, and 2.5T tokens Meaning GLMs. Zhipu&THUDM have also developed GLM-4 which had been the strongest Chinese "GPT-4 killer" until ≈last week.
Enjoyed this paper that plots emergent abilities with pretraining loss on the x-axis, which is actually a suggestion that @OriolVinyalsML also made a few years back: arxiv.org/abs/2403.15796 The paper uses intermediate checkpoints to plot a variety of pretraining losses. For some…
Trends for United States
You might like














