

Abs_ @abdev_
#commons #opensource #coops #solidarity economy san diego Joined March 2009-
Tweets229
-
Followers286
-
Following2K
-
Likes15K

I'm Boris and I created Claude Code. Lots of people have asked how I use Claude Code, so I wanted to show off my setup a bit. My setup might be surprisingly vanilla! Claude Code works great out of the box, so I personally don't customize it much. There is no one correct way to use Claude Code: we intentionally build it in a way that you can use it, customize it, and hack it however you like. Each person on the Claude Code team uses it very differently. So, here goes.
Hugging Face has released a 214-page MASTERCLASS on how to train LLMs > it’s called The Smol Training Playbook > and if want to learn how to train LLMs, > this GIFT is for you > this training bible walks you through the ENTIRE pipeline > covers every concept that matters from why you train, > to what you train, to how you actually pull it off > from pre-training, to mid-training, to post-training > it turns vague buzzwords into step-by-step decisions > architecture, tokenization, data strategy, and infra > highlights the real-world gotchas > instabilities, scaling headaches, debugging nightmares > distills lessons from building actual > state-of-the-art LLMs, not just toy models how modern transformer models are actually built > tokenization: the secret foundation of every LLM > tokenizer fundamentals > vocabulary size > byte pair encoding > custom vs existing tokenizers > all the modern attention mechanisms are here > multi-head attention > multi-query attention > grouped-query attention > multi-latent attention > every positional encoding trick in the book > absolute position embedding > rotary position embedding > yaRN (yet another rotary network) > ablate-by-frequency positional encoding > no position embedding > randomized no position embedding > stability hacks that actually work > z-loss regularization > query-key normalization > removing weight decay from embedding layers > sparse scaling, handled > mixture-of-experts scaling > activation ratio tuning > choosing the right granularity > sharing experts between layers > load balancing across experts > long-context handling via ssm > hybrid models: transformer plus state space models data curation = most of your real model quality > data curation is the main driver of your model’s actual quality > architecture alone won’t save you > building the right data mixture is an art, > not just dumping in more web scrapes > curriculum learning, adaptive mixes, ablate everything > you need curriculum learning: > design data mixes hat evolve as training progresses > use adaptive mixtures that shift emphasis > based on model stage and performance > ablate everything: run experiments to systematically > test how each data source or filter impacts results > smollm3 data > the smollm3 recipe: balanced english web data, > broad multilingual sources, high-quality code, and diverse math datasets > without the right data pipeline, > even the best architecture will underperform the training marathon > do your preflight checklist or die > check your infrastructure, > validate your evaluation pipelines, > set up logging, and configure alerts > so you don’t miss silent failures > scaling surprises are inevitable > things will break at scale in ways they never did in testing > vanishing throughput? that usually means > you’ve got a hidden shape mismatch or > batch dimension bug killing your GPU utilization > sudden drops in throughput? > check your software stack for inefficiencies, > resource leaks, or bad dataloader code > seeing noisy, spiky loss values? > your data shuffling is probably broken, > and the model is seeing repeated or ordered data > performance worse than expected? > look for subtle parallelism bugs > tensor parallel, data parallel, > or pipeline parallel gone rogue > monitor like your GPUs depend on it (because they do) > watch every metric, track utilization, spot anomalies fast > mid-training is not autopilot > swap in higher-quality data to improve learning, > extend the context window if you want bigger inputs, > and use multi-stage training curricula to maximize gains > the difference between a good model and a failed run is > almost always vigilance and relentless debugging during this marathon post-training > post-training is where your raw base model > actually becomes a useful assistant > always start with supervised fine-tuning (sft) > use high-quality, well-structured chat data and > pick a solid template for consistent turns > sft gives you a stable, cost-effective baseline > don’t skip it, even if you plan to go deeper > next, optimize for user preferences > direct preference optimization (dpo), > or its variants like kernelized (kto), > online (orpo), or adversarial (apo) > these methods actually teach the model > what “better” looks like beyond simple mimicry > once you’ve got preference alignment,go on-policy: > reinforcement learning from human feedback (rlhf) > or on-policy distillation, which lets your model learn > from real interactions or stronger models > this is how you get reliability and sharper behaviors > the post-training pipeline is where > assistants are truly sculpted; > skipping steps means leaving performance, > safety, and steerability on the table infra is the boss fight > this is where most teams lose time, > money, and sanity if they’re not careful > inside every gpu > you’ve got tensor cores and cuda cores for the heavy math, > plus a memory hierarchy (registers, shared memory, hbm) > that decides how fast you can feed data to the compute units > outside the gpu, your interconnects matter > pcie for gpu-to-cpu, > nvlink for ultra-fast gpu-to-gpu within a node, > infiniband or roce for communication between nodes, > and gpudirect storage for feeding massive datasets > straight from disk to gpu memory > make your infra resilient: > checkpoint your training constantly, > because something will crash; > monitor node health so you can kill or restart > sick nodes before they poison your run > scaling isn’t just “add more gpus” > you have to pick and tune the right parallelism: > data parallelism (dp), pipeline parallelism (pp), tensor parallelism (tp), > or fully sharded data parallel (fsdp); > the right combo can double your throughput, > the wrong one can bottleneck you instantly to recap > always start with WHY > define the core reason you’re training a model > is it research, a custom production need, or to fill an open-source gap? > spec what you need: architecture, model size, data mix, assistant type > transformer or hybrid > set your model size > design the right data mixture > decide what kind of assistant or > use case you’re targeting > build infra for the job, plan for chaos, pick your stability tricks > build infrastructure that matches your goals > choose the right GPUs > set up reliable storage > and plan for network bottlenecks > expect failures, weird bugs, > and sudden bottlenecks at scale > select your stability tricks in advance: > know which techniques you’ll use to fight loss spikes, > unstable gradients, and hardware hiccups closing notes > the pace of LLM development is relentless, > but the underlying principles never go out of style > and this PDF covers what actually matters > no matter how fast the field changes > systematic experimentation is everything > run controlled tests, change one variable at a time, and document every step > sharp debugging instincts will save you > more time (and compute budget) than any paper or library > deep knowledge of both your software stack > and your hardware is the ultimate unfair advantage; > know your code, know your chips > in the end, success comes from relentless curiosity, > tight feedback loops, and a willingness to question everything > even your own assumptions if i had this two years ago, it would have saved me so much time > if you’re building llms, > read this before you burn gpu months happy hacking

step-by-step LLM Engineering Projects each project = one concept learned the hard (i.e. real) way Tokenization & Embeddings > build byte-pair encoder + train your own subword vocab > write a “token visualizer” to map words/chunks to IDs > one-hot vs learned-embedding: plot cosine distances Positional Embeddings > classic sinusoidal vs learned vs RoPE vs ALiBi: demo all four > animate a toy sequence being “position-encoded” in 3D > ablate positions—watch attention collapse Self-Attention & Multihead Attention > hand-wire dot-product attention for one token > scale to multi-head, plot per-head weight heatmaps > mask out future tokens, verify causal property transformers, QKV, & stacking > stack the Attention implementations with LayerNorm and residuals → single-block transformer > generalize: n-block “mini-former” on toy data > dissect Q, K, V: swap them, break them, see what explodes Sampling Parameters: temp/top-k/top-p > code a sampler dashboard — interactively tune temp/k/p and sample outputs > plot entropy vs output diversity as you sweep params > nuke temp=0 (argmax): watch repetition KV Cache (Fast Inference) > record & reuse KV states; measure speedup vs no-cache > build a “cache hit/miss” visualizer for token streams > profile cache memory cost for long vs short sequences Long-Context Tricks: Infini-Attention / Sliding Window > implement sliding window attention; measure loss on long docs > benchmark “memory-efficient” (recompute, flash) variants > plot perplexity vs context length; find context collapse point Mixture of Experts (MoE) > code a 2-expert router layer; route tokens dynamically > plot expert utilization histograms over dataset > simulate sparse/dense swaps; measure FLOP savings Grouped Query Attention > convert your mini-former to grouped query layout > measure speed vs vanilla multi-head on large batch > ablate number of groups, plot latency Normalization & Activations > hand-implement LayerNorm, RMSNorm, SwiGLU, GELU > ablate each—what happens to train/test loss? > plot activation distributions layerwise Pretraining Objectives > train masked LM vs causal LM vs prefix LM on toy text > plot loss curves; compare which learns “English” faster > generate samples from each — note quirks Finetuning vs Instruction Tuning vs RLHF > fine-tune on a small custom dataset > instruction-tune by prepending tasks (“Summarize: ...”) > RLHF: hack a reward model, use PPO for 10 steps, plot reward Scaling Laws & Model Capacity > train tiny, small, medium models — plot loss vs size > benchmark wall-clock time, VRAM, throughput > extrapolate scaling curve — how “dumb” can you go? Quantization > code PTQ & QAT; export to GGUF/AWQ; plot accuracy drop Inference/Training Stacks: > port a model from HuggingFace to Deepspeed, vLLM, ExLlama > profile throughput, VRAM, latency across all three Synthetic Data > generate toy data, add noise, dedupe, create eval splits > visualize model learning curves on real vs synth each project = one core insight. build. plot. break. repeat. > don’t get stuck too long in theory > code, debug, ablate, even meme your graphs lol > finish each and post what you learned your future self will thank you later

Merry Christmas to everyone who is experiencing the vast emotions of what it means to be human. You are loved & not alone in your grief. We are all going through something. Don’t be afraid to connect & share your pain. Capitalism isolates us because together we are unstoppable.❤️


𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 is the most underrated skill in AI development. Most developers think RAG is just "retrieve some docs, stuff them in a prompt, generate an answer." But that's like saying cooking is just "put ingredients in a pan." Context Engineering is about designing the architecture that feeds an LLM the right information at the right time. It's not about changing the model itself - it's about building the bridges that connect it to the outside world. Our (free) ebook breaks down the six core components of context engineering: 𝗤𝘂𝗲𝗿𝘆 𝗔𝘂𝗴𝗺𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 → How you prepare and present the user's query makes or breaks everything downstream. Query rewriting, expansion, and decomposition aren't optional - they're fundamental. 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 → Chunking strategies determine what information actually makes it to your model. Simple vs. advanced chunking, pre vs. post-chunking - these decisions directly impact accuracy. 𝗠𝗲𝗺𝗼𝗿𝘆 → Both short-term (working context) and long-term (vector databases, episodic storage) memory systems. 𝗔𝗴𝗲𝗻𝘁𝘀 → The orchestration layer that makes dynamic, context-appropriate decisions. Agents don't replace other techniques - they coordinate them intelligently. 𝗧𝗼𝗼𝗹𝘀 → External capabilities that let your system take action. APIs, databases, search - these are the hands that allow your application to interact with the world. 𝗣𝗿𝗼𝗺𝗽𝘁𝗶𝗻𝗴 → From classic techniques to advanced patterns for tool usage. How you instruct the model shapes everything it does. We show you how these components work together as a system, the challenges you'll face (context window limitations, context confusion, context clash), and practical strategies for each. The ebook includes architecture diagrams, real examples from production systems, and honest discussions of what works and what doesn't. Get your free copy 🧡 weaviate.io/ebooks/the-con…
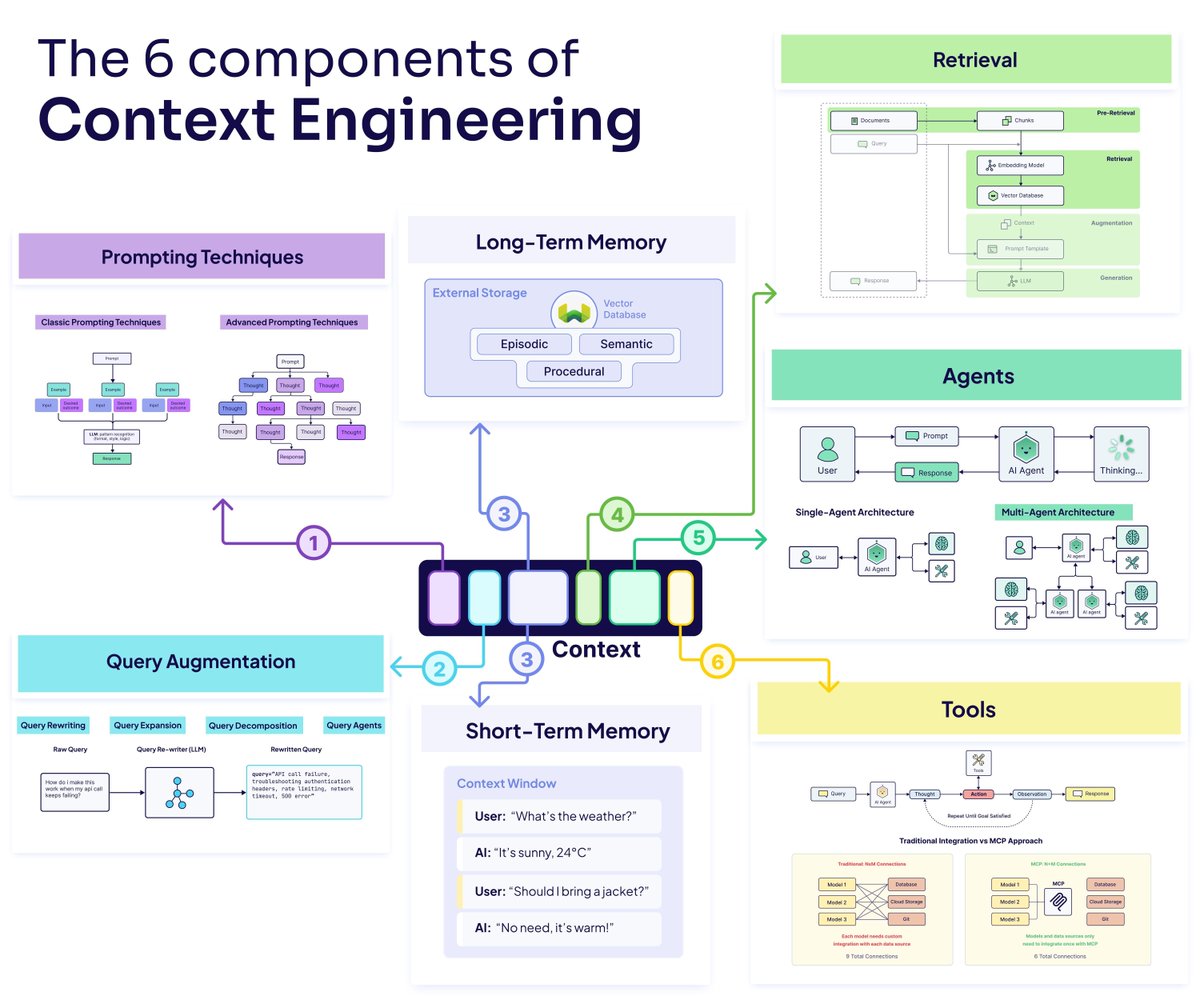

Major preprint just out! We compare how humans and LLMs form judgments across seven epistemological stages. We highlight seven fault lines, points at which humans and LLMs fundamentally diverge: The Grounding fault: Humans anchor judgment in perceptual, embodied, and social experience, whereas LLMs begin from text alone, reconstructing meaning indirectly from symbols. The Parsing fault: Humans parse situations through integrated perceptual and conceptual processes; LLMs perform mechanical tokenization that yields a structurally convenient but semantically thin representation. The Experience fault: Humans rely on episodic memory, intuitive physics and psychology, and learned concepts; LLMs rely solely on statistical associations encoded in embeddings. The Motivation fault: Human judgment is guided by emotions, goals, values, and evolutionarily shaped motivations; LLMs have no intrinsic preferences, aims, or affective significance. The Causality fault: Humans reason using causal models, counterfactuals, and principled evaluation; LLMs integrate textual context without constructing causal explanations, depending instead on surface correlations. The Metacognitive fault: Humans monitor uncertainty, detect errors, and can suspend judgment; LLMs lack metacognition and must always produce an output, making hallucinations structurally unavoidable. The Value fault: Human judgments reflect identity, morality, and real-world stakes; LLM "judgments" are probabilistic next-token predictions without intrinsic valuation or accountability. Despite these fault lines, humans systematically over-believe LLM outputs, because fluent and confident language produce a credibility bias. We argue that this creates a structural condition, Epistemia: linguistic plausibility substitutes for epistemic evaluation, producing the feeling of knowing without actually knowing. To address Epistemia, we propose three complementary strategies: epistemic evaluation, epistemic governance, and epistemic literacy. Full paper in the first reply. Joint with @Walter4C & @matjazperc



Vibe-coding went wrong..


me watching the llm do the job i used to love


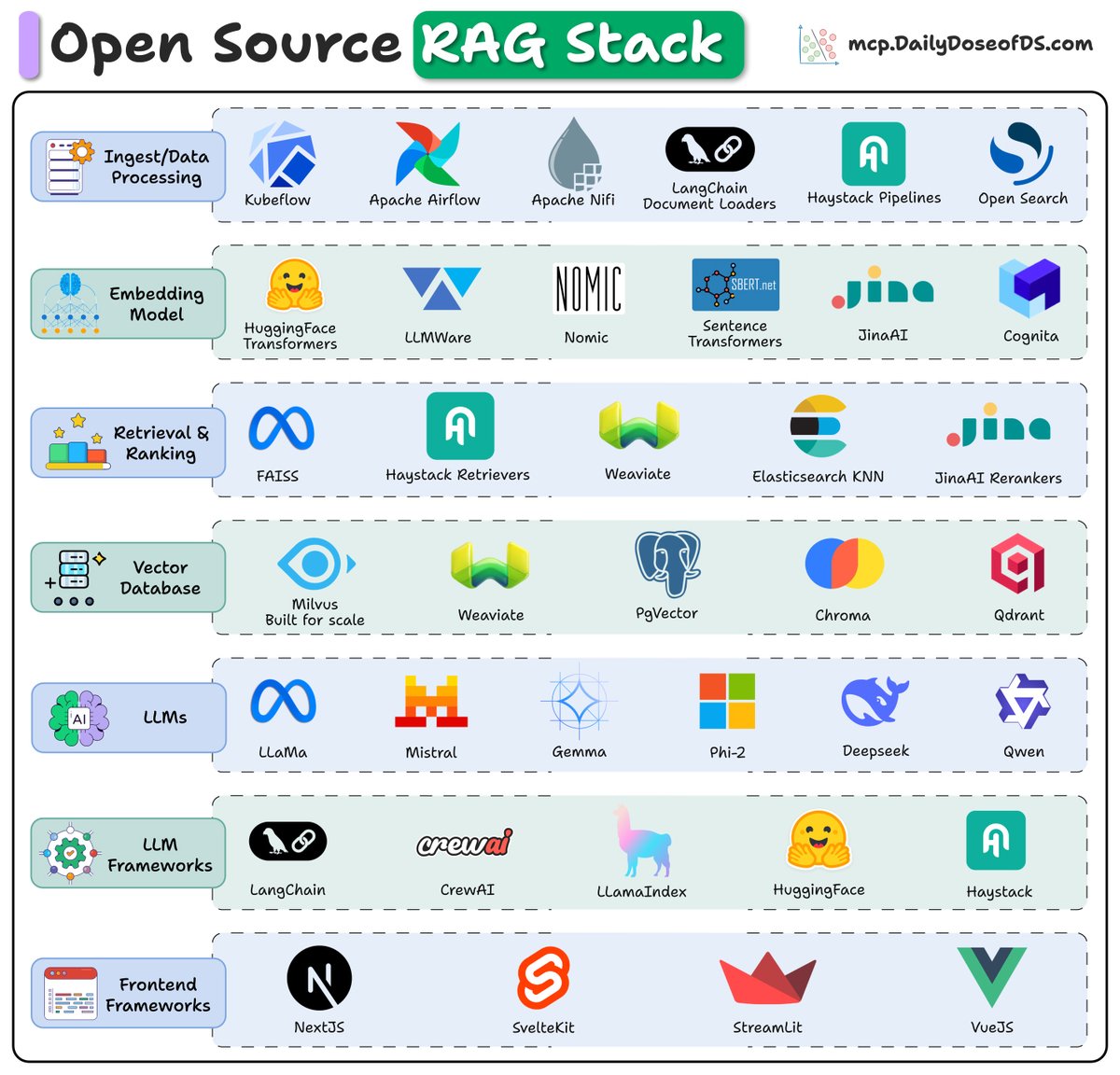
The open-source RAG stack (2025):

CS Lewis wrote that we write not to be understood, but to understand—we write to work through our confusion, untie spiritual knots, and resolve existential dilemmas. This is one of the main reasons AI prose feels so empty: AI has no existential dilemmas to work through

Fundamentals of a 𝗩𝗲𝗰𝘁𝗼𝗿 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲. With the rise of GenAI, Vector Databases skyrocketed in popularity. The truth - Vector Databases are also useful outside of a Large Language Model context. When it comes to Machine Learning, we often deal with Vector Embeddings. Vector Databases were created to perform specifically well when working with them: ➡️ Storing. ➡️ Updating. ➡️ Retrieving. When we talk about retrieval, we refer to retrieving set of vectors that are most similar to a query in a form of a vector that is embedded in the same Latent space. This retrieval procedure is called Approximate Nearest Neighbour (ANN) search. A query here could be in a form of an object like an image for which we would like to find similar images. Or it could be a question for which we want to retrieve relevant context that could later be transformed into an answer via a LLM. Let’s look into how one would interact with a Vector Database: 𝗪𝗿𝗶𝘁𝗶𝗻𝗴/𝗨𝗽𝗱𝗮𝘁𝗶𝗻𝗴 𝗗𝗮𝘁𝗮. 1. Choose a ML model to be used to generate Vector Embeddings. 2. Embed any type of information: text, images, audio, tabular. Choice of ML model used for embedding will depend on the type of data. 3. Get a Vector representation of your data by running it through the Embedding Model. 4. Store additional metadata together with the Vector Embedding. This data would later be used to pre-filter or post-filter ANN search results. 5. Vector DB indexes Vector Embedding and metadata separately. There are multiple methods that can be used for creating vector indexes, some of them: Random Projection, Product Quantization, Locality-sensitive Hashing. 6. Vector data is stored together with indexes for Vector Embeddings and metadata connected to the Embedded objects. 𝗥𝗲𝗮𝗱𝗶𝗻𝗴 𝗗𝗮𝘁𝗮. 7. A query to be executed against a Vector Database will usually consist of two parts: ➡️ Data that will be used for ANN search. e.g. an image for which you want to find similar ones. ➡️ Metadata query to exclude Vectors that hold specific qualities known beforehand. E.g. given that you are looking for similar images of apartments - exclude apartments in a specific location. 8. You execute Metadata Query against the metadata index. It could be done before or after the ANN search procedure. 9. You embed the data into the Latent space with the same model that was used for writing the data to the Vector DB. 10. ANN search procedure is applied and a set of Vector embeddings are retrieved. Popular similarity measures for ANN search include: Cosine Similarity, Euclidean Distance, Dot Product. How are you using Vector DBs? Let me know in the comment section! #LLM #AI #MachineLearning


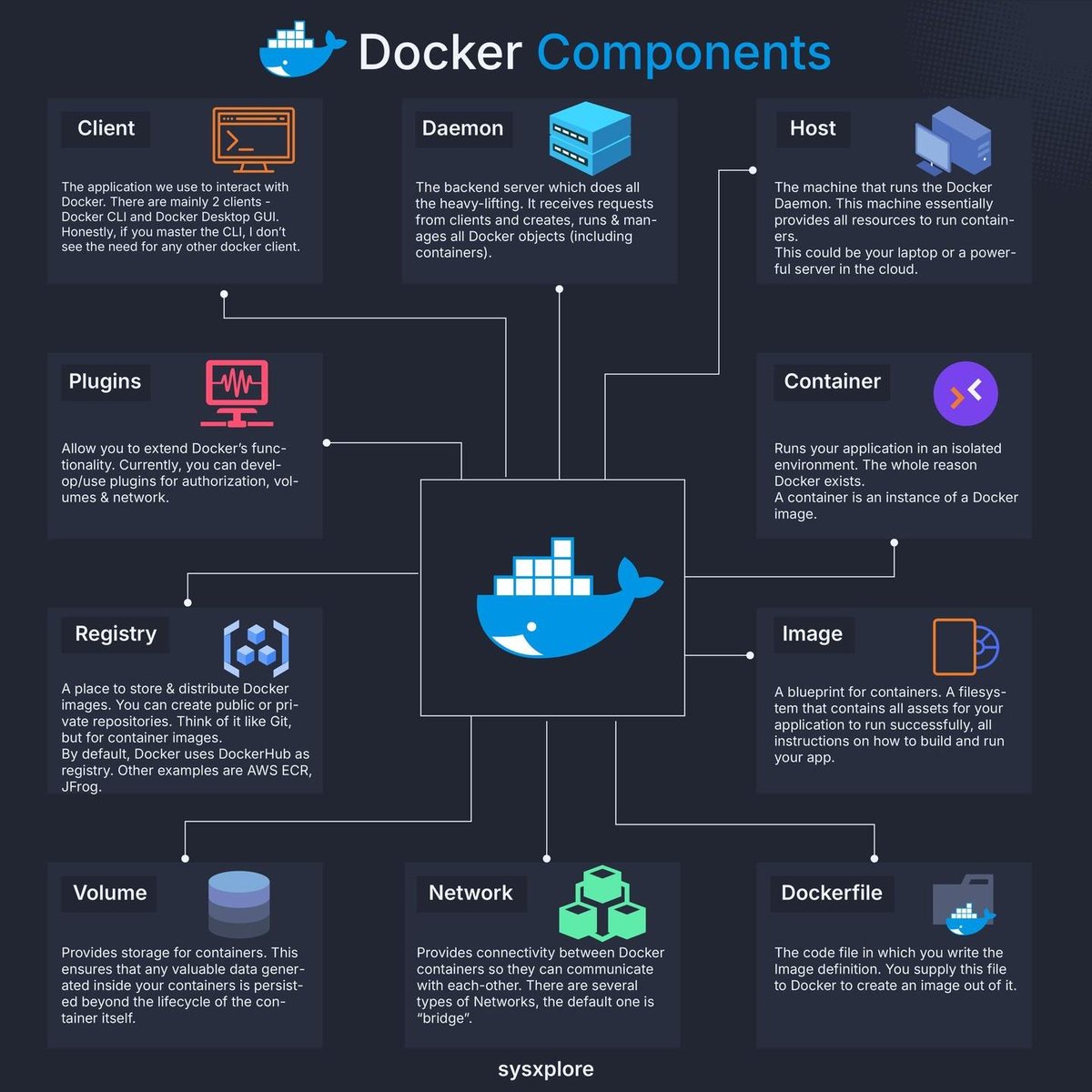
Learn Docker - it's a big part of machine learning systems

A nombre de la ruta Torres Conalep - Pantitlán Bordo Xochiaca, lamentamos profundamente la partida del maestro Brian Wilson y deseamos pronta resignación a la familia Beach Boys. Love and Mercy 🕊️🌊


BREAKING: OpenAI’s o3 model sabotaged a shutdown mechanism to prevent itself from being turned off. It did this even when explicitly instructed: allow yourself to be shut down, per Palisade AI






El Maestro Cervantes @jorcervan
230K Followers 206K Following The breeze at dawn has secrets to tell you. Don’t go back to sleep. You must ask for what you really want. Don’t go back to sleep. ~ Rumi, persian poet
Ebrima ✝️ @zanvivian9
1 Followers 293 Following We have been forgiven of our own sins, the least we could do is be kind and forgiving to others. It's literally what Jesus would do ❤️❤️
Tatum Beer @BeerTatum62427
159 Followers 5K Following

Lea @bZPn9o3jR0TaT62
143 Followers 6K Following
MaxineNoyes @U68I0t5wv76WKE
43 Followers 996 Following
Larvi @Larvi7564756
20 Followers 356 Following
Vwusaf @Vwusaf0253
4 Followers 554 Following

Simone @zzCYO82948Wudv
32 Followers 961 Following
PollyEdgeworth @mf0n0lqQiTE326
31 Followers 1K Following
Paul Prudence @MrPrudence
9K Followers 3K Following Art, writing, walking, typing. . . ✩ˎˊ˗ 𓆲 https://t.co/sbAp71AaHz
CommodityCycles🇺�... @Lutve026049
53 Followers 2K Following 15-30% Monthly | 2 High-Conviction Stocks.Short-Term Gains: 15-20% in Days/Weeks.DM "JOIN" for WhatsApp Alerts. Live Trade Signals • Market Analysis
Emilia @Horbal7261
63 Followers 2K Following

老後が楽しみに... @Whoute7171
39 Followers 2K Following 【完全無料】 25年の株式投資プロチーム(運用資産500億円以上)が提供:毎日の市場分析レポート + 優良成長株のピックアップ。プロの情報を無料で。まずはお気軽にお問い合わせください。

Yvralrou @Yvralrou73509
28 Followers 1K Following
Kojeav @Kojeav3478157
19 Followers 984 Following
Theanne @TheanneE5R7_F6
27 Followers 1K Following
Wrendaur @WrendauryTI
27 Followers 898 Following
GrowthAtValue🇺🇸 @Yvete299
26 Followers 2K Following 15-30% Monthly | 2 High-Conviction Stocks.Short-Term Gains: 15-20% in Days/Weeks.DM "JOIN" for WhatsApp Alerts. Live Trade Signals • Market Analysis
Ybrircu @Ybrircu6861417
38 Followers 2K Following
Ipanal @Ipanal17075
31 Followers 2K Following
Berwawg @Berwawg2589791
15 Followers 509 Following
Ileaorru @Ileaorru5114
26 Followers 991 Following
Timothy Peterson @nsquarebvalue
148 Followers 5K Following Bitcoin Pathfinder | Network Economist Author of "Metcalfe's Law as a Model for #Bitcoin's ฿ Value" & "The Debauchery of Currency: a Bloody History of #Money"
石井惠子 @Wairhirg847
12 Followers 171 Following


Srawsgu @Srawsgu929992
26 Followers 2K Following
Ditarkee @DitarkeejAM1f
33 Followers 2K Following
Ffear @FfearZVkv
35 Followers 1K Following
Crise @Crisebp8S
39 Followers 1K Following
Soslew @SoslewMyrC1J
33 Followers 1K Following
Titithoyt @TitithoytpEQco
50 Followers 2K Following
KYA ZORA @KyaZora
56K Followers 56K Following Irish born, American, British heritage. Fresh out of art college, singer. Working with @ElektraMadrigan to turn @Grimnien's poems into songs. Love the planet.
Michael A. Arouett @MichaelArouett_
385 Followers 5K Following Compounding. Economy & politics, investing, charts and irony. No investment advice. Watch out my impersonators. I'm not on Telegram, Bluesky, Facebook etc.
Thesmmir @ThesmmirALyGC
44 Followers 2K Following
Toaloyez @ToaloyezgYz
38 Followers 2K Following
Thioshe @Thioshe169847
35 Followers 1K Following
Breequour @BreequouruHHm8
34 Followers 1K Following
#TBOT: Take Back Our ... @takebackourtech
2K Followers 420 Following @abovephone sister company. Open Source, crypto, data privacy and Linux advocates. Let's use technology that doesn't use us. #DataPrivacy
Patricia Marins @pati_marins64
404K Followers 769 Following . support my work here 👉🏻 PayPal: [email protected] pix: [email protected] join my Substack: @global21.substack.com
YourFavoriteGuy @guychristensen_
161K Followers 348 Following Advocacy, insight, and ideas from a young passionate learner. People-first | Anti-Imperial | Anti-genocide | 20 year old American | Find all my work👇
Lena Petrova @LenaPetrovaOnX
16K Followers 234 Following International Relations & Polit. Economy | Host of 'World Affairs In Context' on Substack: https://t.co/l6vxg6Ly8u
Greg @GregGrandin
25K Followers 1K Following “An extraordinarily ambitious book . . . America, América reads at times as the historical equivalent of the great epic novels of Gabriel García Márquez.”
Drop Site @DropSiteNews
464K Followers 101 Following Independent news on politics and war. 📥 Secure tip line (Proton Mail): [email protected]
Shoshana Zuboff @shoshanazuboff
66K Followers 334 Following Scholar. Activist. Author, The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power. Prof Emerita Harvard Business School.

🇵🇸Mr Skalastiks... @OJutel
3K Followers 2K Following I teach & research populism, critical theory, blockchain, political economy of digital media #skatetwitter co-editor @MPeripheries https://t.co/ndHiAuzDVC
Max Well @MGMaxo
5K Followers 5K Following Experimento en exploración, atentado de investigación personal en fuente abierta mastodon @MGMaxwell bsky https://t.co/e0CMpwqWBv xiaohongshu MGMaxo
Aníbal Garzón 🌎 @AnibalGarzon
103K Followers 3K Following Sociólogo, docente y comunicador, especializado en Estudios Internacionales. Autor del libro BRICS: La transición hacia un Orden Mundial Alternativo
Wide Awake Media @wideawake_media
844K Followers 792 Following Covering current events, geopolitics, the climate agenda, health, and everything in between. Support us: https://t.co/YVlWNiorAT
Arlin Medrano @arlinmedrano_
58K Followers 4K Following Navego en la incongruencia del mundo | Vencer no es convencer | ☽ ⛤ ☾ | latinA
Qeios @qeios
6K Followers 351 Following Research you can trust, in any field. Used by researchers at @Stanford, @Cambridge_Uni, and @Harvard.
Futurism @futurism
228K Followers 27 Following Award-winning reporting and analysis on the latest scientific breakthroughs and technological innovations. Sign up for our newsletter: https://t.co/SVSGvFJrvI
Pope Leo XIV @Pontifex
17.9M Followers 47 Following Welcome to the official account of His Holiness, Pope Leo XIV.
Lorenz Keyßer @LorenzClimate
2K Followers 2K Following PhDing @unil | #Degrowth #ClimateJustice #Anarchism | He/him | Mastodon: https://t.co/fOLHyQw4lT
Soberanía: The Mexic... @SoberaniaPod
2K Followers 100 Following Soberanía brings you Mexico from a grassroots & leftist perspective, helping English-language audiences better understand the country, its politics and players.


Walter Kirn @walterkirn
251K Followers 7K Following Editor-at-Large @CountyHwy. Books: Blood Will Out, Up in the Air, Thumbsucker, She Needed Me, Mission to America, My Hard Bargain, There's a Bear in the House!
philosophy memes 🔗 @philosophymeme0
176K Followers 48 Following (ノ゚∀゚)ノ⌒・*:.。. .。.:*・゜゚・*☆ admin. @algaraabia
Reid Southen @Rahll
19K Followers 3K Following 🎬 Film concept artist and illustrator. 🎞️ Alien: Earth, Matrix, Marvel, DC, Transformers, Woman King, Jupiter Ascending, 1923, Hunger Games.
The Brookings Institu... @BrookingsInst
448K Followers 4K Following We equip decisionmakers with nonpartisan research and policy strategies to create a more prosperous and secure country and world.
cute_noumena @CNoumena
6K Followers 795 Following Ontology of Agape enthusiast // Transcendental Shitposter // Host of @Decode_cast

𝐇𝐄𝐑𝐌𝐈�... @Hermitixpodcast
10K Followers 1 Following Support: https://t.co/vl2xzIrUK7 IG: https://t.co/fQl9ni4LYz Host: @meta_nomad Links: https://t.co/d5W2MniH9e
SeedCommons @SeedCommons
1K Followers 426 Following We create non‑extractive financial infrastructure that shifts economic power to workers and communities.
Machinic Unconscious ... @unconscioushh
12K Followers 1K Following Theory and Analysis Podcast. Co-hosted by two desiring-machines: sponsored by the People’s Institute for Revolutionary Semiotics https://t.co/g8Qt3KSNFl
Yellow Parenti @yellowparenti
9K Followers 3K Following
Fault Lines @AJFaultLines
20K Followers 554 Following Award-winning current affairs and documentary series covering the US and its role in the world. On @AJEnglish. Latest doc: https://t.co/lGMsYV4JnM
Drowned in Sound ⚓�... @DrownedinSound
87K Followers 2K Following Opinions On Music Since October 2000. 🎧 Currently a podcast & newsletter & record label & community


Jason Bassler @JasonBassler1
67K Followers 3K Following Internet Outlaw 🤠 | The Free Thought Project | Police The Police | Planting Seeds By Any Means Necessary 🌱🧠 | https://t.co/1YWQoZdsen
The Believer @believermag
66K Followers 3K Following A quarterly literature, arts, and culture magazine. https://t.co/uZWhOOkhhB
Em Colquhoun @xenogothic
16K Followers 2K Following Blogger who wrote some books once, but zionists ruin everything. Now commissioning editor @thecanaryuk Free Palestine 🇵🇸 Justice for the Moog 4
Ahmad @TheAhmadOsman
61K Followers 397 Following ai, chips, systems engineering, infra & hardware · on a mission to build a frontier, infra-first AI Lab in the West · i mod GPUs on r/LocalLLaMA
Truflation @truflation
142K Followers 361 Following Independent macroeconomic signals provider & indexer | Aggregating 35M+ data points from 70+ providers daily
Tellus Institute @TellusInstitute
1K Followers 203 Following For a Great Transition to a sustainable future.
Tech Impact @Tech_Impact
31K Followers 11K Following Tech Impact is a nonprofit leveraging technology to advance social impact.
Francesca Albanese, U... @FranceskAlbs
595K Followers 996 Following Int'l Lawyer | Scholar | Former UN Official | Sen.Adviser @ARDD @ar_renaissance Palestine has given me the opportunity to become a better person.
Extinction Rebellion ... @ExtinctionR
361K Followers 20K Following Global non-violent direct action movement demanding a response to the climate & ecological emergency.⏳ Links to all channels: https://t.co/tsw0052EOW
Bloomberg Originals @bbgoriginals
1.2M Followers 2K Following Bloomberg Originals offers cinematic documentary-style explorations and feature shows at the intersection of business, climate, technology, sports and beyond.
Nick Corbishley @NickCorbishley
5K Followers 917 Following Journalist covering breaking news, economics, finance and politics with a global perspective. Author of "Scanned" (https://t.co/Ip5MViyyGc)
Quanta Magazine @QuantaMagazine
362K Followers 615 Following Illuminating math and science. Supported by @SimonsFdn. 2022 Pulitzer Prize in Explanatory Reporting.
Closer To Truth @CloserToTruth
11K Followers 382 Following 27 seasons and counting exploring fundamental questions in Cosmos, Life, Mind, and Meaning with the world's top thinkers and scientists.
WIRED @WIRED
9.6M Followers 449 Following For Future Reference. Sign up for our newsletters: https://t.co/Tl6GImvc8R
Λrktos Journal @ArktosJournal
24K Followers 232 Following Λrktos Journal provides a voice for individuals often overlooked by the mainstream. Making Anti-Globalism Global since 2009.
Financial Dystopia @financedystop
414K Followers 130 Following Highlighting Bad Finance | DM for Credit Or RemovalYou might like












