

apoorve kalot @Transwert
YourGuide | Going from zero to somewhere | Alma-mater @ IIT-Hyderabad | Start-ups | crypto | Applied ML transwert.github.io Bangalore Joined March 2018-
Tweets416
-
Followers109
-
Following134
-
Likes2K

The TurboQuant paper (ICLR 2026) contains serious issues in how it describes RaBitQ, including incorrect technical claims and misleading theory/experiment comparisons. We flagged these issues to the authors before submission. They acknowledged them, but chose not to fix them. The paper was later accepted and widely promoted by Google, reaching tens of millions of views. We’re speaking up now because once a misleading narrative spreads, it becomes much harder to correct. We’ve written a public comment on openreview (openreview.net/forum?id=tO3AS…). We would greatly appreciate your attention and help in sharing it.

Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI

The funniest thing about TurboQuant is that not only is none of it new, every part of what we've implemented is very old. We are just rediscovering tricks video game developers had to use in the 90s. FWHT decorrelation → DCT in JPEG/MPEG decorrelation Lloyd-Max 16-centroid codebook → 256-color palette (VQ codebook) Norm + quantized unit vector → Quake's norm vector table 128-elm blocks with 4-bit indices → S3 texture compression ADC lookup table (VecInfer) → Dot-product LUTs for lighting Per-block scale factor → ADPCM audio (scale per block + quantized residuals)

llama.cpp at 100k stars now that 90% of the code worldwide is being written by AI agents, I predict that within 3-6 months, 90% of all AI agents will be running locally with llama.cpp 😄 Jokes aside, I am going to use this small milestone as an opportunity to reflect a bit on the project and the state of AI from the perspective of local applications. There is a lot to say and discuss and yet it feels less and less important to try to make a point. Opinions about viability of local LLMs are strongly polarized, details are overlooked, the scientific approach is lacking. Arguments are predominantly based on vibes and hype waves. One thing is clear though - local LLMs are used more and more. I expect this trend to continue and likely 2026 will end up being one of the most important years for the local AI movement. I admit that I didn't expect the agentic era to come so quickly to the local LLM space. One year ago, the available models were too computationally expensive for doing long-context tasks. There wasn't an obvious path towards meaningful agentic applications. The memory and compute requirements were huge. Last summer, with the release of gpt-oss, things started to change. It was the first time we saw a glimpse of tool calling that actually works well within the resource constraints of our daily devices. Later in the year, even better models were released and by now, useful local agentic workflows are a reality. Comparing local vs hosted capabilities at a given moment of time is pointless. To try put things into perspective: - We don't need frontier intelligence to automate searches and sending emails - We don't need trillion parameter models to be able to summarize articles or technical documents - We don't need massive GPU data centers to control our home appliances or turn the lights off in the garage I believe that there is a certain level of intelligence we as humans can comprehend and meaningfully utilize to improve our working process. Beyond that level, access to more intelligence becomes unnecessary at best and counterproductive at worst. I also believe that that level of useful artificial intelligence is completely within reach locally and it has always been just a matter of implementing the right software stack to bring it to the end user. With llama.cpp, I am confident that we continue to be on the right track of building that software stack! The llama.cpp project is going stronger than ever. With more than 1500 contributors, the project keeps growing steadily. From technical point of view, I think that llama.cpp + ggml is the only solution that actually makes sense. That is, the software stack must run efficiently on every possible device, hardware and operating system. The technology is too important to be vendor-locked. It has to be developed in the open, by the community, together with the independent hardware vendors. This is the only right way to build something that will truly make a difference in the long run. I won't try to convince you about what is currently and will be possible with local AI. We will just continue to build as usual. I am confident that after the smoke clears and we look objectively at what we have built together, the benefits will be obvious to everyone. Big shoutout to all llama.cpp maintainers. I feel extremely lucky to be able to work together with so many talented contributors. Every day I learn something new and I feel there is so much more cool stuff that we are going to build. Also, I am really thankful that the project continues to have reliable partners to support it! Cheers!


@futurebeast_04 Keep going mate 💪 it happens 😁

My dear front-end developers (and anyone who’s interested in the future of interfaces): I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept): Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow
Tasted rajasthani cuisine for the first time with my friend(the guy who hired me currently in the org) @Transwert Solid 9/10 🔥😅 ...

@futurebeast_04 Welcome to job hunt 😄 👹
Also added a little challenge for fellow Tarnished: Can you identify which Elden Ring Background track maps to each level/boss? 👀⚔️ Bonus challenge: If you collect all items and clear all mobs without dying once, there’s a hidden special message from me XD
Had some free time so turned my resume into a Mario-style (Elden Ring Audio theme based) interactive Resume 🎮 (Link: lnkd.in/gRHJ8NVh) Built with vanilla JS + HTML5 Canvas, where: each company: level project: enemy encounter tech stack: collectibles + Boss Fight!!!!

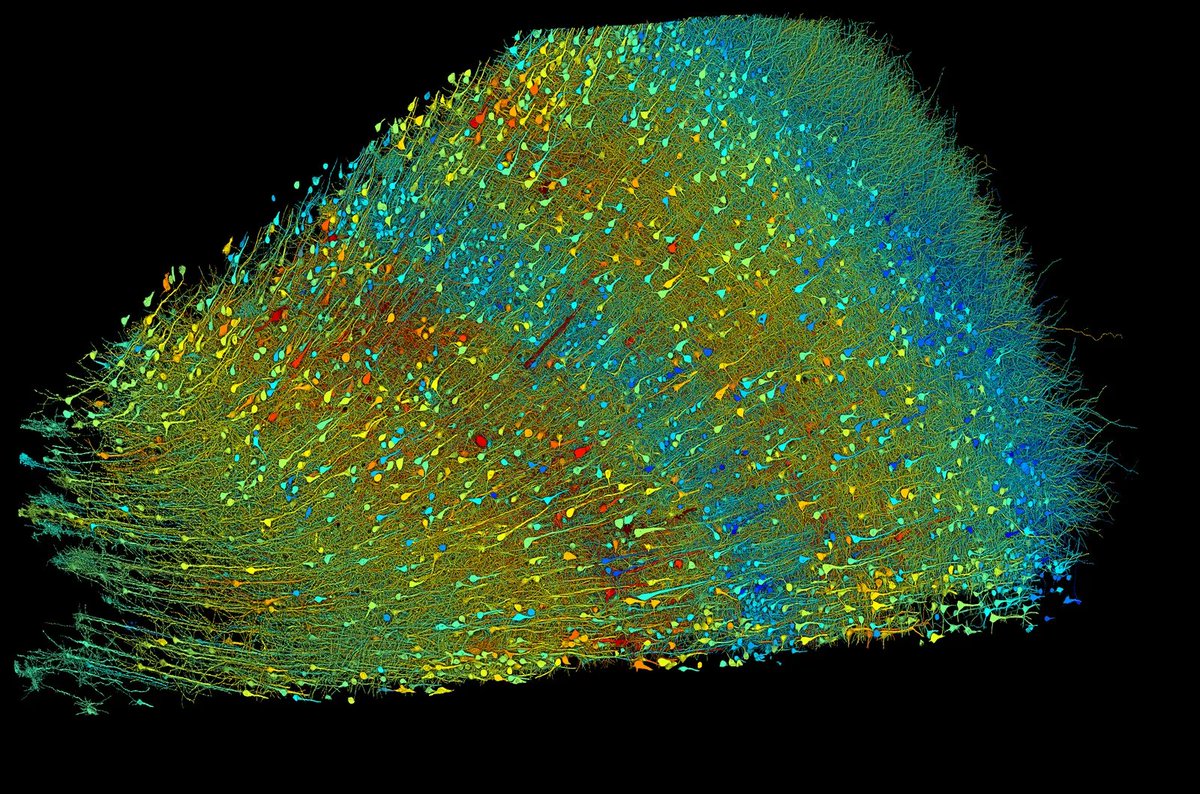
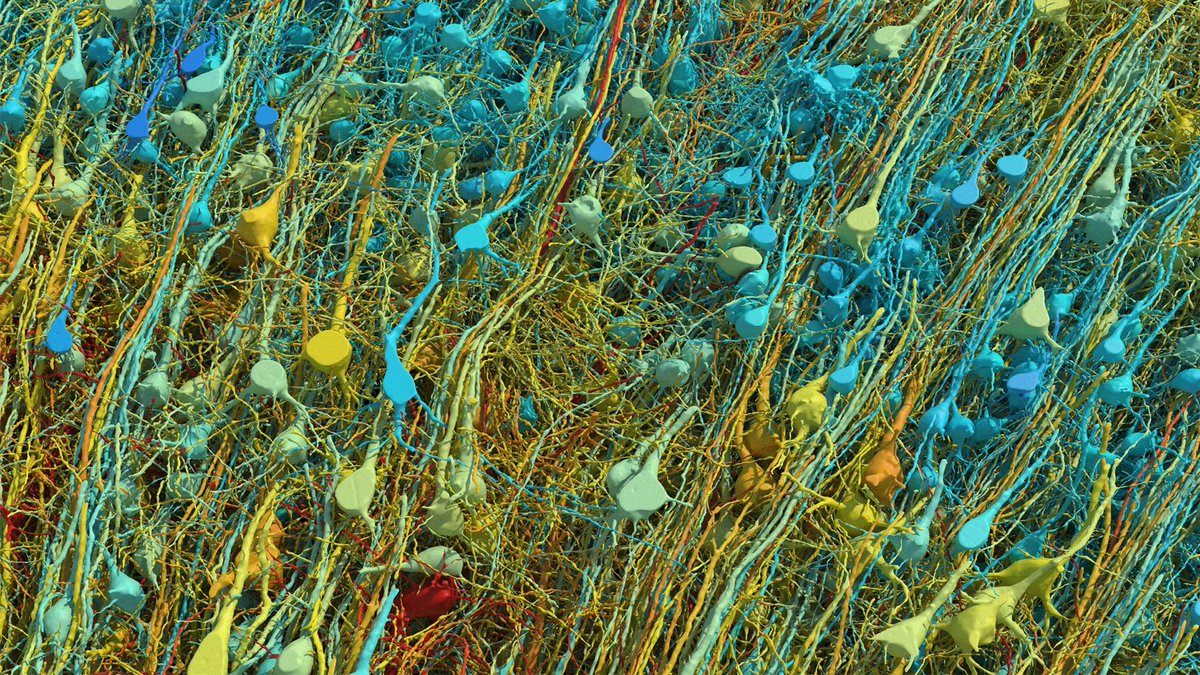
The math on this project should mass-humble every AI lab on the planet. 1 cubic millimeter. One-millionth of a human brain. Harvard and Google spent 10 years mapping it. The imaging alone took 326 days. They sliced the tissue into 5,000 wafers each 30 nanometers thick, ran them through a $6 million electron microscope, then needed Google’s ML models to stitch the 3D reconstruction because no human team could process the output. The result: 57,000 cells, 150 million synapses, 230 millimeters of blood vessels, compressed into 1.4 petabytes of raw data. For context, 1.4 petabytes is roughly 1.4 million gigabytes. From a speck smaller than a grain of rice. Now scale that. The full human brain is one million times larger. Mapping the whole thing at this resolution would produce approximately 1.4 zettabytes of data. That’s roughly equal to all the data generated on Earth in a single year. The storage alone would cost an estimated $50 billion and require a 140-acre data center, which would make it the largest on the planet. And they found things textbooks don’t contain. One neuron had over 5,000 connection points. Some axons had coiled themselves into tight whorls for completely unknown reasons. Pairs of cell clusters grew in mirror images of each other. Jeff Lichtman, the Harvard lead, said there’s “a chasm between what we already know and what we need to know.” This is why the next step isn’t a human brain. It’s a mouse hippocampus, 10 cubic millimeters, over the next five years. Because even a mouse brain is 1,000x larger than what they just mapped, and the full mouse connectome is the proof of concept before anyone attempts the human one. We’re building AI systems that loosely mimic neural networks while still unable to fully read the wiring diagram of a single cubic millimeter of the thing we’re trying to imitate. The original is 1.4 petabytes per millionth of its volume. Every AI model on Earth fits in a fraction of that. The brain runs on 20 watts and fits in your skull. The data center required to merely describe one-millionth of it would span 140 acres.

🚨: Scientists mapped 1 mm³ of a human brain ─ less than a grain of rice ─ and a microscopic cosmos appeared.

I find it very funny when anyone feels confident that they've figured out agentic programming, even funnier when they're trying to teach others how to do it. I've been working on OpenCode since May of last year and I still have days (like yesterday) where I'm not even sure any of this is a good idea lol
I end up landing on "yes, these models are an incredible tool" but it's still all very confusing, lots of tangled thoughts and emotions and realities.
I badly miss the mundane coding tasks that broke up my days/weeks, the ones where you put on the headphones and just bang out 600 lines of code. But, no question, replacing those hours of my time with a few minutes of waiting on an agent is a boost and worth being excited about, despite the mixed emotions.
Then there's the distance that can creep in between you and the codebase if you start getting apathetic. I think it's pretty common at this point to make even small changes by prompting the models. It's less friction than finding the relevant code and making the change yourself. And less friction seems to win, must be some law of the universe or some shit. When most or all of your interactions with a codebase start flowing through the models, you start to lose track of where things live, which abstractions/components are carrying the weight, etc. It's a scary feeling to wake up and realizing you can't even reliably @

STILL HIRING: AI ENGINEER fullstack. high agency. AI-native. you ship fast and don't need hand-holding. NA/EU + startup experience preferred but not necessary. we build startups alongside some of the biggest names in their industries + custom dev work for SMBs. more inbound than we can handle and growing fast, need cracked devs yesterday. DM me experience and or book a call: calendly.com/d/ct87-jx8-9ks
@futurebeast_04 Great 😃 just busy spiralling through life 🥂

There are few Schengen countries which one should know aren't very fond of travelers from India. Italy is one of them. I know many people who had to cancel their plans as they only had Italy in their itinerary, and slots were never released. This happens more for North India; however, for the Consulate in Mumbai, it's better. Also, if a married couple is traveling together and one has a Schengen visa, they both can apply under the previous Schengen visa holder category. You can get this in writing from VFS; we have had a couple of clients who were allowed with this. My recommendation, do not opt for Italy as a first Schengen destination or a primary destination. GREECE another such country, which should be best avoided as a primary destination, currently they don't have a visa processor and aren't taking any application from India (joke of a destination). I have some contacts there and from what I have gathered this will take time, a country which doesn't take Indian tourists seriously should be best avoided. I have personally seen them rejecting unecessarily, I have a huge sample size to prove they just tick one reason (common) and reject Indian applications. They were notoriously famous for holding passport and sending rejection letters just before the travel. Its not like visas don't come from here, but best avoided. Do one thing go and read their google reviews (Greece Embassy Delhi) Austria they are another absurd Embassy, they will randomly reject your visa and give stupid reasons. Appeal may work, but there are phases when they don't care. There was a time when we saw a pattern of bulk refusal to applicants from different city, different application dates getting refusal letters on the same date with a blank refusal letter, no efforts done to even put a signal. Again, its not like that people don't get the visa from the above countries, they do get but honestly visas aren't cheap, add the processor fees and other variables you are atleast looking at ₹40k INR for a family of 4. Put it to better use, I have seen many families vacation being ruined. There are many excellent countries and who give great due respect to the application and here's a small list. 1.) Netherlands- My personal favorite, dutch bureaucracy is something which I have always admired but at the same time will recommend to folks having good ITR, and stable profiles in India. Ideal ITR range above 15 lkhs. Do not try with prior refusals. Processing speed moderate to slow. Known for multiple entry and longer validity. 2.) Czech Republic- A strict Embassy, which doesn't want you to change anything in itinerary post visa issuance but a very very good Embassy, no ideal ITR range, one of the cheapest Schengen countries to visit. Processing speed fast. Known for Single-entry and exact days visa. 3.) Finland - A very balanced Embassy, can be strict but processes application with care, don't use illogical itinerary or a pseudo itinerary like 10 days in Helsinki. They carefully read docs and process application on an average in 2 weeks, Expensive country. ITR. Known for Single entry and exact days itinerary. 4.) France- very fast, probably fastest in India, not recomended for folks with ITR under 10 lkhs. Do not apply if you have a lot of talking regarding your application. Know for longer validity and multiple entry. 5.) Switzerland- Very fast, Better to apply with high income for obvious reasons but no such ITR variance data to say lower may be rejected. Appointments are easily avaialable, no additional docs allowed beyond checklist. One of the only embassies that gives flat out 90 days visa with 30 days stay to even a first timer.

Planning a trip to #Italy and getting your #SchengenVisa then read this before you make a single booking or even plan your travels. Hurdle 1: Italy has jurisdiction so you cannot just walk-in any location across India and apply for your visa. Hurdle 2: Italy has two



2 servers. 8 CPUS. Processing 8 billion ticks per day. Under 2 milliseconds. Running at 20% CPU utilization. Sometimes the best infrastructure is the one you build yourself. That's our market feed data infrastructure at Sahi. This processes high speed feeds from the Exchanges and builds the critical data products that power your trading experience on Sahi. Rather than throw hardware at the problem, our engineering team relied upon thoughtful architecture choices: → Lock-free Rust actors → Pre-serialized message caching → Time-bucketed partitioning → Token-aware database routing Full technical deep-dive: sahi.com/blogs/from-exc… @Sahi_HQ

the only things you need to know: your account has a base score and it runs before your tweet is evaluated: verified accounts: +100 automatic unverified accounts: max +55 then multiplied by your follower/following ratio (only really a factor if it’s really bad), multiplied by your “restriction status” no more manual engineering rules, grok 100% determines the algorithm your posts live or die in the first 30mins with “velocity”: minutes 0-5: shown to ~5-10% of your followers + small outside of network sample minutes 5-15: if engagement is strong, shown to 20-30% of followers and larger OON minutes 15-30: if still performing, enters “for you” feeds at scale older posts get trimmed and not given a second chance because they’re competing with newer posts that have stronger velocity signals engagement weights: >reply engaged by author: +75 >reply: +13.5 >profile click: +12 >repost: +1.0 >like: +0.5 >report: -369 (instant death) >videos don’t really matter. 50% video completion is only +0.005 no “relevance” ranking between posts, the score is the score and it doesn’t change based on what else is in the feed or what’s popular today

We have open-sourced our new 𝕏 algorithm, powered by the same transformer architecture as xAI's Grok model. Check it out here: github.com/xai-org/x-algo…

Fun fact: The 1998 paper that introduced Google and PageRank to the world ends with this acknowledgment: "Supported by the National Science Foundation under Cooperative Agreement IRI-9411306. Funding also provided by DARPA and NASA." Sergey Brin was on an NSF Graduate Fellowship. Larry Page was a PhD student on the grant. Google—now worth $2 trillion—exists because American taxpayers funded "the Stanford Integrated Digital Library Project." Not a startup garage myth. A government grant. Every time someone says public research funding "picks winners and losers" or "crowds out private innovation," remember: the most dominant technology company of the 21st century was incubated entirely with public money, inside a public university, by researchers on federal fellowships and grants. The private sector didn't see it coming. VCs passed. The government funded it anyway—not because it would become Google, but because fundamental research into information retrieval seemed worth understanding. That's the point. You can't predict which grants will change the world. You fund the science and let researchers explore. The internet (DARPA). GPS (DoD). Touchscreens (CIA/NSF). mRNA vaccines (NIH). Google (NSF/DARPA/NASA). Public investment in basic research isn't wasteful spending. It's the seed corn of the entire modern economy.

Scaled from 1,000 to 100,000 users. Here's what broke. At 5,000 users: - Single database became the bottleneck - Added read replicas At 20,000 users: - Session storage overwhelmed Redis - Switched to JWT tokens At 50,000 users: - File uploads killed our servers - Moved to S3 with presigned URLs At 75,000 users: - Search became unusable - Implemented Elasticsearch At 100,000 users: - DNS became single point of failure - Multi-region with Route53 failover Every stage felt like the final architecture. None of them were. Scaling isn't a destination. It's a continuous series of bottleneck discoveries.

Abhishek (Ablution) S... @Abhishek_KrS
112 Followers 91 Following
Arpit pathak @coder1709
1 Followers 50 Following
Sandipan @theneuralguy
1K Followers 3K Following EEE'26 | schrodinger pro max mini lite v69.69 | ML ,DL,Backend ,Electronics(tweaking is my love:) ) |ML Intern | High on caffeine...

Junior Severe👨�... @SEVEREJunior1
91 Followers 1K Following Downloading....Cloud/DevOps Engineer. CS50 certified | AWS certified
Dauawki @Dauawki4973
78 Followers 1K Following
Rupeeezy @SetabAli9
88 Followers 2K Following India's Trusted Trading & Investment Platform for 20+ Years. Follow for updates on Stocks, MFs, F&O, IPO, etc. RA Disclaimer: https://t.co/jUeSs1Z17z



Rahul Mathu @KathelenGama
96 Followers 771 Following Now: Pre-Seed Investor @DeVC_India || Prev: Founder @VerakInsurance (acq. by ID) || Kindly DM on https://t.co/mv42k4bg3h || Views are my own


Thijs Bergkamp @ThijsBergkamp
47 Followers 7K Following
Jayachandra Naidu Raj... @rootc_jc
81 Followers 266 Following 21 | Inference Engineer @amd | Physical AI | Prev. ML Compilers Research @cse_iith | UG @cse_iith @IITHyderabad | posts/opinions are personal
Win-ay @vinay_kumar_ch_
8 Followers 119 Following 25 l Code | Gym | Senior Data Engineer | IIT Hyderabad
Viraj_thakur @vivek_sing89816
155 Followers 1K Following


Milin Bhade @MilinBhade
162 Followers 6K Following Post Grad Student at IISc, Bangalore Masters in Computer Science & Automation
Shakeel Ahmed @shakeel_9966
3 Followers 113 Following
Aditya Gulati @GulatiAditya10
11 Followers 49 Following

Akshat Loya @akshat_loya
23 Followers 102 Following

Olawale Tofade 🧘�... @OlawaleTofade
950 Followers 2K Following Senior Site Reliability Engineer | passionate about DevOps and all things tech. #DevOps #Arsenal
Uday Beswal @UdayBeswal
18 Followers 147 Following Remote Software Developer | Undergraduate Engineering Student at TIET, Patiala | Ex - Research Intern (ML) @ DRDO, Ministry of Defence
Harsh Maheshwari @HarshMheshwari
2K Followers 2K Following Enthusiastic about #GenerativeAI #DataScience 🤖 | Constantly curious learner 🌱 | Applied scientist 2 at @amazon | Writer at @medium | @IITKGP Graduate
Lewis 🇺🇸 @ctjlewis
46K Followers 21K Following Startup counterculture. LLMs. If you think I might be able to help you with something, ask.

Akash Singh @AkashicMarga
364 Followers 1K Following आ नो भद्रा: क्रतवो यन्तु विश्वत: | Exploring Curiosity !!
Banoth Devender @BanothDeve81577
4 Followers 10 Following
Shreyas Havaldar @_toolazyto_
772 Followers 686 Following Presidential Fellow PhD Student @Columbia | @GoogleDeepMind | @IITHyderabad CS '22 | Causality & LLMs | Somewhere, something incredible is waiting to be known
Agvg @agvgoutham
16 Followers 416 Following
hitesh sehrawat @hiteshsehrawat_
11 Followers 22 Following
G-man stan stan @gargu_fake
156 Followers 678 Following registered sex defender | Forbes tatti under 30

Arpit pathak @Arpit9454
6 Followers 88 Following
Lalalalalalala @anuragnaik5_
13 Followers 41 Following ''i might be the writer, but you'll always be the words'' - Ben Maxfield


RaghavGupta1992 @RaghavGuptaAsr
8 Followers 90 Following Machine Learning @IIT-Hyderabad. ex-: Backend @ Grey Orange. ex-: CS+Physics @ BITS-Pilani. ex-: ML in Digital Mar. @ Deepflux. ex-: Computer Vision @ Frinks
Aditya Agrawal @adityaagr799
120 Followers 532 Following Co-founder @FrinksAI | Alumni @IITHyderabad | Musician | Travel enthusiast
Saurabh Gawali @ThebrokeSaurabh
21 Followers 233 Following | Building a Clean Mobility Startup | IITH|@adiabatictechnology
Amitanshu Sahoo @AmitanshuSahoo
15 Followers 61 Following
u @Uttam89675905
2 Followers 120 Following
konda sridhar babu @konda4212
23 Followers 71 Following Promoter of KONDA satyalaxmi gardens &Srinivasa poultry farm karimnagar.
Arpit pathak @coder1709
1 Followers 50 Following
Conner Bean @ConnerBean
945 Followers 372 Following securing agents & autonomy // prev @stripe, @awscloud // husband, father (x2), engineer, avid midwesterner

Ahmad @TheAhmadOsman
62K Followers 396 Following ai, chips, systems engineering, infra & hardware · on a mission to build a frontier, infra-first AI Lab in the West · i mod GPUs on r/LocalLLaMA
Debasish (দেব�... @debasishg
13K Followers 651 Following Programmer. Author: Functional and Reactive Domain Modeling (Manning 2016), DSLs In Action (Manning 2010). Father. Husband. Seinfeld fanboy. FP aficionado.

saurabh parmar @saurabhparmar
797 Followers 132 Following Ex- Founder : B2C & B2B businesses 🧠 | Teacher, Guest Author & Consultant | helping connect the dots between business, branding & digital media+ Digital Nomad
Sandipan @theneuralguy
1K Followers 3K Following EEE'26 | schrodinger pro max mini lite v69.69 | ML ,DL,Backend ,Electronics(tweaking is my love:) ) |ML Intern | High on caffeine...
Rupeeezy @SetabAli9
88 Followers 2K Following India's Trusted Trading & Investment Platform for 20+ Years. Follow for updates on Stocks, MFs, F&O, IPO, etc. RA Disclaimer: https://t.co/jUeSs1Z17z

Bahram Shakerin @BahramShakerin
5K Followers 390 Following PhD in hep-th/ph. Interested in Theoretical Physics, Fundamental Physics, Philosophy, Art & Aesthetics. I am an Existentialist. #QuantumGravity
Sarge @sgt3v
3K Followers 201 Following Developer of @neocortexlink & @readyplayerme MSc Software Engineer, Indie Game Dev Joining game jams in different places 🇹🇷🇩🇪🇪🇪🇫🇮🇸🇪🇱🇻🇯🇵


Тsфdiиg @tsoding
115K Followers 415 Following Recreational Programming - https://t.co/0cNzC7z24Y - https://t.co/EilSXwJsXC - https://t.co/cPjxUvz266 ⠀⢀⣰⣾⡿⣶⣿⠿⣶ ⢠⣼⣿⣿⣷⣿⣿⣶⠉ ⢸⣿⣿⣿⣿⣿⣿⠀⠀
Milin Bhade @MilinBhade
162 Followers 6K Following Post Grad Student at IISc, Bangalore Masters in Computer Science & Automation
Aditya Gulati @GulatiAditya10
11 Followers 49 Following
Brett Adcock @adcock_brett
562K Followers 21 Following @figure_robot (AI robots) @hark_labs (personal AGI) @cover_thz (weapon detection) @flyArcher (flying cars)
Gergely Orosz @GergelyOrosz
339K Followers 3K Following Writing @Pragmatic_Eng, the #1 software engineering newsletter on Substack. Author of @EngGuidebook. Formerly Uber & Skype.
Rowan Cheung @rowancheung
592K Followers 563 Following Founder of the world’s most read daily AI newsletter @therundownai. Sharing the latest developments in the world of artificial intelligence.
Harrison Kinsley @Sentdex
106K Followers 429 Following gpus and tractors. Director of AI and Engineering @ https://t.co/H4St8dd1ip Neural networks from Scratch book: https://t.co/hyMkWyUP7R https://t.co/8WGZRkUGsn
Olawale Tofade 🧘�... @OlawaleTofade
950 Followers 2K Following Senior Site Reliability Engineer | passionate about DevOps and all things tech. #DevOps #Arsenal

Michael Levan👨🏻... @TheNJDevOpsGuy
9K Followers 702 Following Building How AI Runs in Production | AI Architect & Forward Deployed Engineer | CNCF Ambassador | 4x Author & International Speaker
OlorenAI @OlorenAI
330 Followers 98 Following Always looking for friends to work with whether you are a big enterprise or someone looking for a job. Email us at [email protected]
Uday Beswal @UdayBeswal
18 Followers 147 Following Remote Software Developer | Undergraduate Engineering Student at TIET, Patiala | Ex - Research Intern (ML) @ DRDO, Ministry of Defence
Harsh Maheshwari @HarshMheshwari
2K Followers 2K Following Enthusiastic about #GenerativeAI #DataScience 🤖 | Constantly curious learner 🌱 | Applied scientist 2 at @amazon | Writer at @medium | @IITKGP Graduate
AK @_akhaliq
505K Followers 3K Following AI research paper tweets, ML @Gradio (acq. by @HuggingFace 🤗) dm for promo ,submit papers here: https://t.co/UzmYN5XOCi
François Chollet @fchollet
697K Followers 825 Following Co-founder @ndea. Co-founder @arcprize. Creator of Keras and ARC-AGI. Author of 'Deep Learning with Python'.

Eric Jang @ericjang11
134K Followers 4K Following
Soumith Chintala @soumithchintala
307K Followers 1K Following Building new things @thinkymachines. Also dabble in robotics at NYU. Cofounded @PyTorch. AI is delicious when it is accessible and open-source.


Google DeepMind @GoogleDeepMind
1.5M Followers 278 Following The engine room of @Google. Building AI safely and responsibly to solve the world’s most complex problems. Join us: https://t.co/jUHQA27iBL
Sebastian Raschka @rasbt
464K Followers 1K Following ML/AI research engineer. Ex stats professor. Author of "Build a Large Language Model From Scratch" (https://t.co/O8LAAMRzzW) & reasoning (https://t.co/5TueQKx2Fk)
Yann LeCun @ylecun
1.2M Followers 786 Following Professor at NYU & Executive Chairman at AMI Labs. Ex-Chief AI Scientist at Meta. Researcher in AI, Machine Learning, Robotics, etc. ACM Turing Award Laureate.
Sherjil Ozair @sherjilozair
13K Followers 4K Following prometheus | founder @GeneralAgentsCo | previously autopilot @tesla, deep learning @googledeepmind, phd https://t.co/dxgb6gimCf, cs @iitdelhi
Lewis 🇺🇸 @ctjlewis
46K Followers 21K Following Startup counterculture. LLMs. If you think I might be able to help you with something, ask.
typedfemale @typedfemale
45K Followers 554 Following a really exciting new account "advanced pytorch user" - @cHHillee alt: @typedalt
Nemo @thecaptain_nemo
35K Followers 3K Following the human instrumentality project will not be televised




Beff (e/acc) @beffjezos
238K Followers 3K Following founder @ e/acc // thermo king @extropic // Kardashev scaling is all you need
kache @yacineMTB
295K Followers 6K Following reinforcement learning, robots. prev eng @ x, stripe. 6'3 (height) tensorpunk subscribe to read my blog!
John Carmack @ID_AA_Carmack
2.3M Followers 286 Following AGI at Keen Technologies, former CTO Oculus VR, Founder Id Software and Armadillo AerospaceYou might like






