
Announcing RecurrentGemma! github.com/google-deepmin… - A 2B model with open weights based on Griffin - Replaces transformer with mix of gated linear recurrences and local attention - Competitive with Gemma-2B on downstream evals - Higher throughput when sampling long sequences
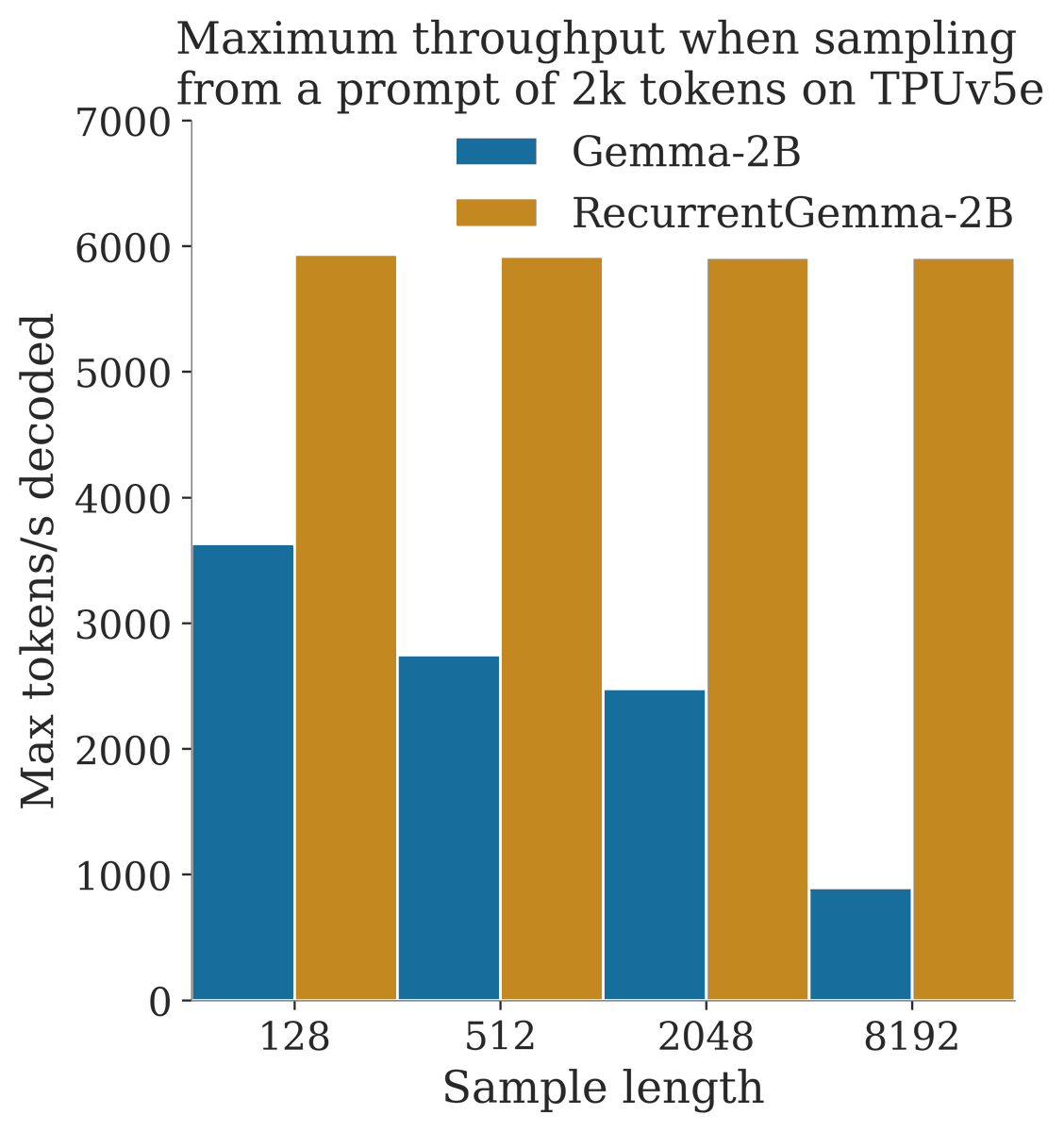
Building on ideas from SSMs and LSTMs, Griffin matches transformer performance without global attention, achieving faster inference on long sequences. arxiv.org/abs/2402.19427 See @sohamde_'s great thread for more details: x.com/sohamde_/statu…

Building on ideas from SSMs and LSTMs, Griffin matches transformer performance without global attention, achieving faster inference on long sequences. arxiv.org/abs/2402.19427 See @sohamde_'s great thread for more details: x.com/sohamde_/statu…

@SamuelMLSmith Exciting work! Curious why you didn't train a larger version. Was it due to computational budget, or are there scalability limits with the training process or model performance?

@SamuelMLSmith “Competitive performance to Gemma-2B” on both short and long context?

@SamuelMLSmith Hi Samuel. Curious why the RNN width does not get bigger than the model width? is that to save decoding memory? That should have little training cost right?
