

Runcible @Runcible_OS
Turn accelerating complexity into your strategic advantage. runcible.com Joined March 2025-
Tweets165
-
Followers89
-
Following2
-
Likes48

At present, you cannot legally deploy AI in regulated industries because no one can certify that the AI is not hallucinating its answers. This is not a problem the major AI companies can solve. It would take five to ten years of focused research to get there, even with large teams. It is not the kind of problem that yields simply because you assign more engineers to it. Its not even an engineering peoblem. The only group close to solving it, with a functional solution that now needs to be made commercially ready, is @Runcible_OS . I know that because I work there. Creating a governance layer that allows you to verify that AI output conforms to regulatory standards is extraordinarily complex. You are not just building a model. You are building a certifiable trust structure around that model. None of the major AI companies are addressing this. Many are not even examining the problem. The few that are looking at it are approaching it from the wrong direction. The path they are taking will not get them to a certifiable, regulation-compliant solution.
This is exactly what I have been predicting all along. LLMs will become a commodity. Prices will continue to drop. The real profit will not be made on the model itself, but on the governance layers and tooling that turn an LLM into a reliable profit center for specific industries. The highest value will be created in industries that require extreme precision. Those are the sectors where mistakes are expensive, liability is real, and error tolerance is low. That is where the money is. And yet, those are precisely the industries that are currently most excluded from using LLMs to solve their highest-value problems. Not because the models are incapable, but because there is no commercially available governance layer that can do what Runcible does. Until that layer exists, LLMs remain toys for low-risk applications and marketing demos. Once it exists, the real markets open. @Runcible_OS

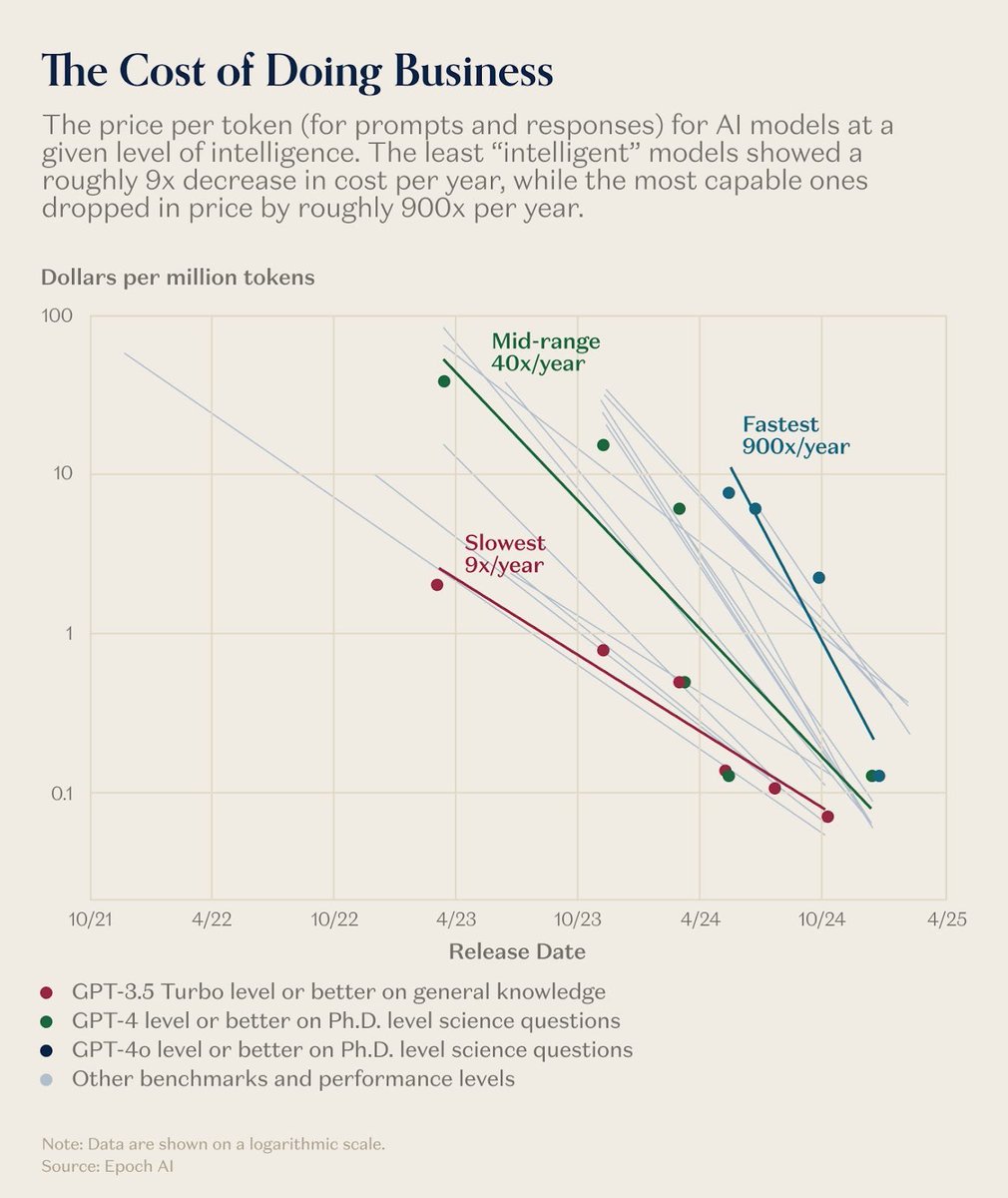
LLM token prices are collapsing fast, and the collapse is steepest at the top end. The least "intelligent" models get about 9× cheaper per year, mid-tier models drop about 40× per year, and the most capable models fall about 900× per year. Was same with "Moore’s Law, the best
COMPUTABILITY IS TOO SMALL A QUESTION Framing the question of computability requires solving the questions of *commensurability and closure*. Our (my organization's) analysis suggests that the "correlation trap" is limiting advancement toward AGI and SI - and for logical reasons: physics, computer science, and mathematics rely on low dimensional closure and mathematical reducibility, while the 'hard problems' of high dimensionality and commensurability requires semantic commensurability and supply vs demand closure. Oddly, the LLMs are fantastic at the latter, despite the attempts to achieve it through traditional low dimensional closure. As someone who has worked in this field for decades (computability) I find this circumstance as another example of Kuhn's gravestones. On the other hand our organization has effectively solved this problem technically. While the real problem is lack of understanding of these issues in the extant field.

RUNCIBLE is coming.
Stanford Paper explains why LLMs require our Runcible Governance Layer.
New Stanford paper argues that LLMs already provide the raw skills for AGI, but they still need a coordination layer on top. Here the LLM is a fast pattern store, while a slower controller should choose which patterns to use, enforce constraints, and keep track of state. To

(Runcible Update) Today we created the first pass at Runcible Reality Description Language (RDL). But what does that mean? Think of the evolutionary sequences of: ... 0) Grammars of Paradigms: embodiment > narration > mythology > philosophy > empiricism > science > operationalism ... 1) Reduction (expressibility): Mathematical Reducibility > Programmatic Reducibility > Operational Reducibility > Verbal Reducibility > Artificial Neural Network Reducibility ... 2) Closure: Intuitive/Embodied Closure: Basic survival-based instincts or heuristics (e.g., immediate sensory feedback or trial-and-error in pre-literate societies), providing rudimentary decidability without formal structure. > Logical Closure: Affirmative justification through internal consistency (aligning with early philosophy or positiva tests), but vulnerable to unfalsifiable assumptions. > Empirical Closure: Falsification via external correspondence (e.g., scientific method), adding verifiability but still limited to observable phenomena. > Operational Closure: Constructive procedures that demand actionable, repeatable steps (e.g., operationalism), ensuring computability but potentially ignoring ethics or reciprocity. > Reciprocal/Adversarial Closure: Full integration of necessity, sufficiency, reciprocity/symmetry, and coherence under adversarial testing, yielding auditable, ethical, and liability-enforcing decisions (as in RDL and Runcible's "closure layer"). ... 3) Tests: Justification (Positiva) > Falsification (Negativa) > Adversarialism (constructive logic and empirical correspondence) ... 4) Programming: Sequential Programming > Functional Programming > Object Oriented Programming > Reality Description Language (RDL) "RDL is an operational grammar, reliant on adversarial survival, by both operational construction and empirical correspondence, for testing the computability, ethics, and testifiability of any statement in human language."-- RDL Formalized our work in a way that closed the gaps in LLM computability due to it's tendency to drift. This is revolutionary in no small part because until we solved the method and the grammars it was thought not possible. Cheers
--"Our RDL constrains AI output via negativa: claims that cannot be warranted, audited, or held accountable are not expressible. That sentence: - Is short. - Is hard. - Cannot be misunderstood. - Survives hostile questioning. What we are actually defining is: A computable boundary between language and reality. Most people will take months to realize the significance of that."-- by Brad Werrell
THE FUNDAMENTAL DIFFERENCE BETWEEN OUR RUNCIBLE AI WORK AND MAINSTREAM AI WORK Economics, as an extension of physics, and equal to physics in its demand for acquisition in support equilibration sufficient to defeat entropy as a means of persistence, is the only viable system of thought and terminology for the production of rational, possible, ethical, moral, and liable and therefore restitutable behavior. It's the only means of commensurable exchange of information serving equally accessible means of reasoning between human neural networks and machine neural networks. The fact that the fields of math, programming, and the hard sciences are 'stuck' on cardinality and ordinality reducible to quantities, rather than natural indexing is the reason this is not understood in the field. In Runcible we use the same techniques used in court which is to test first principles and all of them are reducible to economic terms and totally absent any moral framing or bias. For measurement we use natural indexing by sequences of terms, not unnatural (cardinal, ordinal) in indexing. This is effectively a system of supply and demand and relies on what is effectively marginal indifference in referential and transformal categories (see category theory in mathematics). This is once again part of my consistent commentary that our work in the grammars has united the sciences into a single universally commensurable value neutral system of thought, ethics, politics and law. And that the present defect caused by academic siloing is spreading error in most fields faster than it can be corrected, despite the near abandonment of science in social sciences since the introgression of the frankfurt school of non-science into the american and western academy.
AN IMPORTANT THOUGHT Because our modeling of the world evolved from the physical to the economic, we tend to think that's a dependency. And instead, I might extend my argument by saying that for human reasoning, the physical world and how we think of it in cardinal indexing and measure by mathematical reduction is a subset of the economic world and we think of it in natural indexing and measure by satisfaction of supply and demand. It helps us humans a bit to grasp that all cardinality and ordinality is effectively a statistical game rather than the purity we presume in mathematical reasoning. And that naturality is effectively the neural equivalent of a statistical game (predictive) by dendritic computation that we can barely observe. I put all this 'error' in the category of 'mathiness' which is one of the principle traps in both physics, and philosophy, and possibly why philosophy stalled until we developed twenty first century cognitive science to escape the failure of the non-sciences. I hope this has some value to you. Curt Doolittle
--"Hyperdeflation of the cost of intelligence will not stay constrained to the data centers - it will spread outward from these benchmarks to the rest of the economy."-- Alexander Wissner-Gross via Peter Diamandis Almost everything negative I read and hear about AI is nonsense.
WHY RUNCIBLE IS AHEAD OF THE AI CURVE --"Prediction (speculative): The next discontinuity [in AI] will not come from “more parameters” per se; it will come from architectures that treat the base model as a proposal engine inside a verified workflow—where most value is created by (i) typed intermediate representations, (ii) external checkers, (iii) provenance ledgers, and (iv) explicit abstention/deferral policies. Proof/verification work is an early, clean instance of that shift. That direction is consistent with our program: you are formalizing the governance/closure layer; others are discovering it by necessity in narrower domains."--
CONVERGENCE --"This result is exactly what you’d expect when models are forced to represent physical reality with high fidelity. Under sufficient pressure, different architectures don’t learn arbitrary embeddings — they converge on the same underlying structure, because the space of physically valid representations is extremely constrained. This isn’t model magic. It’s reality imposing geometry."-- @DavidWall9987 Now, of course, in our work I've been producing unification by reduction to first principles of pressure, spin, vibration, charge, differentiation, positive and negative entropy. But I did so to remain consistent with human cognitive and linguistic capacity at human scale - so that we could understand the universe as consistent at all scales from our POV outward - overcoming 'mathiness' in the foundations of physics. But humans are limited by causal dimensionality and ai's with their n-dimensional manifolds are not. So we should expect and we do and we observe, that the ai's can produce patterns of relations in n-dimensionality beyond the limits observable by humans. Yet once that pattern is identified and reduced to some analogy to human experience, then humans can again use it like any other. (It's not like QM and the standard model are reductions to human experience at this point either.) Anyway. I feel privileged to live in this time. And I am just as happy if someone else discovers these things. Share the burden after all. The end point for some is acknowledgement the end point for others like myself is empowerment of mankind. Cheers Curt Doolittle

@askalphaxiv This result is exactly what you’d expect when models are forced to represent physical reality with high fidelity. Under sufficient pressure, different architectures don’t learn arbitrary embeddings — they converge on the same underlying structure, because the space of physically
(Runcible) Ariella has positioned her work with Runcible - in this case medical - as writing a brief for Runcible to start with. Of course, because we have been in the business of writing strategy, marketing, creative, and tech briefs. I have to work with this idea for a bit. How can we help people write briefs for AI's that give enough context for it to decide?
A minimal “Primer” that forces correct classification of our work on Runcible Definitions + dependency graph a) Terms: Paradigm, grammar-as-measurement, domain, claim(s), test(s), constraint(s), closure, decidability, ledger (record) b) Diagram: Text → Claim Graph → Tests → Evidence Bindings → Verdicts → Output Artifact Theorem statements (short, ruthless) a) No closure without proof obligations. b) No audit without provenance. c) No liability assignment without typed verdicts + trace. d) No high-liability deployment without admissible abstention. e) No cross-domain decidability without a baseline measurement grammar (Natural Law invariants).
NLI One-Line Tests - If it isn’t decidable, it isn’t law. - If it isn’t reciprocal, it’s parasitism. - If power isn’t liable, it’s illegitimate. - If enforcement isn’t symmetric, reduce scope. - If exit is blocked, conflict follows. (an interesting LLM interpretation of
Q: Curt: What does a Runcible Protocol Consist of? Producing a protocol requires performing the means of disambiguating the causal dimensions necessary to provide decidability, organizing them into a set of tests (process) which together determine the result, and emiting an audit trail (telemetry). So a protocol consists of making a checklist of tests constructed from first principles that must be determined in order to satisfy decidability - satisfaction of the demand for infallibility in the context in question. Our 'work' is in discovering the first principles, the spectrum of values along that dimensions, and dependency order of their execution if there is one. By and large, the law already works this way. The problem is (a) other than 'equity', the law has no baseline until our work, and (b) human capacity for causal density is easily overloaded especially in the context of potential bias, whereas the AI does not have that problem. So really what we do when we write our volumes/books (dig for first principles) is all the work. The problem is that the AI seems to be able to help us get there with our direction (intuition) but it cannot do so alone. I "might" have figured out how to teach it to do it, but not yet sure. I have a test protocol designed but have not yet run and debugged it. Again, this is what the law does. We are 'completing' the science of law. "Reduction of contexts to protocols (tests) that deliver decidability". This is also why the AI industry is failing to produce other than the correlation trap under real-world closure instead of math, programming and other logic 'puzzles'. They use simple closure (internal). The difference is that the physical sciences are generally problems of combinatorics (what's possible) whereas the behavioral sciences consist of problems of reductions (distillations). So these are two different domains of problem solving and therefore differnt means of closure. What I find interesting is the mainstream's emphasis on the puzzles, science, and math despite that they are subject to internal closre and 'trivial' by comparison to questions of human behavior at various scales. Hence why we use natural indexing (words) as measurements not cardinality or ordinality, we use economic reasoning - meaning equilibria, we use supply and demand, we use satisfaction of demand for infallibility in the context in question, and we use liability as the limit gate. To the naive person this does not look like a peer to mathematics, but it is. Most math is a trivial geometry by comparison, while natural measurements are a far deeper geometry with second and third order effects - and more. SO while higher dimensional math seeks to produce projections as means of commensurability in our work we produce reductions to causality as that means of commensurability. The mathematical equivalent is a very high dimensional application of category theory. This means we are working with what is actually the natural 'measurement, math, or logic' of the llm. So to some degree we are not fighting it, and the mainstream is fighting the LLM. Of course, I worked on computable legal decidability, Markov chains incorporated into state engines since the 80s, creating dynamically adapting software. I'd solved reducibility to action and = episodic memory. What I didn't solve was attention. That's the magic that in retrospect we all missed - largely because we lacked the computing power so use 'over-reduction' producing 'over-determinism' that LLMs today avoid. The magic of hardware today is that it's absurdly powerful compared to the past, which 'relieved' the technology industry of trying to oversimplify (reduce) causality. We don't have to reduce to human levels of commensurability. We can work with absurdly high dimensionality. In retrospect, though we saw the use of GPUs to solve matrix problems by the early 2000s, the scale of that compute was still 'magic' until some crazy folks through enough money and enough hardware at the problem to overcome the minimum dimensional competition necessary to produce the LLMs.
We understand Palantir. Palantir creates domain specific ontologies. At Runcible we create *the* ontology - for universal commensurability - so that we can test possibility, truth, ethics, and morality. So it's more that Palantir's goal is correct for discrete problems while our goal is correct for universal problems: economics, sociology, politics, and law. We mere humans need both general and specific solutions.


Capitol City Landlord @LandlordCity
108 Followers 775 Following YES, there is a rental application fee. NO, you can’t have your security deposit back. Benevolent Landlord. Net worth: $2,816,309.44
Tile @whevx
7 Followers 485 Following
Paul Hess @PaulHess07
211 Followers 322 Following Völkisch, Vrill, Aryanism, NS, Dharma warrior, Dispenser of white pills. Hyperborea & Atlantis 2.0
R @RayOrlowski
199 Followers 1K Following
Wexterity @Wexterity
528 Followers 7K Following The social media account for @Vinyxdev and @Vincent6182_ Founder of the company @ambush_dev OLD account: @Vincent6182

Ian Vecmanis @Ian_Vecmanis
402 Followers 2K Following
Buba @Buba1165314
933 Followers 6K Following
Liberteer @5thGenMinuteman
85 Followers 723 Following 🇺🇲 Master of None | Anti-Collectivist | Pro-Nuclear | Global Liberty Enthusiast | NLI Advocate

Shockley @Will_B_Shockley
8 Followers 72 Following

Σ_TN_ᛟ∞ @E_TN_OG
147 Followers 125 Following - Appalachian spine. Western mind. - Counterweight to institutional drift. - R1b-M405

Asha Logos @AshaLogos
80K Followers 8K Following Seeking to think and speak clearly. Asha Contra Druj.


Mike Emmons @mikeemmons23
110 Followers 319 Following Forging foundations for the future through this age of crises.


J A @JaredAberach
75 Followers 211 Following
xtradlnia @xtragonia1
15 Followers 2K Following

Domum Deo recipiemus ... @AfaoGroyper
137 Followers 544 Following American holocaust survivor. We will have our home again.
washinglineman @washinglineman
278 Followers 1K Following

Dorian Green @DorianGreenEU
52 Followers 3K Following my interests: entrepreneurship, cyberpunk, cryptocurrency, rock music
Arcology Research @ArcologyTech
1K Followers 1K Following "The Study and Implementation of humane, durable built-environments, and how they guide behavior towards an objective ideal." I build things for my friends.
Williamson Petukan @William_Petukan
22 Followers 303 Following
Richard Nikoley @rnikoley
6K Followers 457 Following An American Abroad. Japan, France, Mexico, and Thailand. I tell stories. https://t.co/WPhS2dZTxz
DJ Racism @BasedLawyer
268 Followers 1K Following
Thanh Diệu @thanhdieu021
8 Followers 147 Following
agorist 🏴 @agoristoperator
602 Followers 2K Following
rollingricks @rollingrick77
35 Followers 635 Following
Rishi 🌓 @blanktablets
502 Followers 603 Following Regenaissance-Man🍎 your inability to relate is a skill issue.
Joshua Ebner @JoshuaEbner
3K Followers 2K Following I help companies build AI systems that drive growth and profit. Ex Apple, Cornell physics. 20 years in the data industry.


FatherIsSpeaking @Father_Speaking
447 Followers 1K Following Paternal Revanchist Mastermind. “The response should not shy away from making claims which are politically incorrect, as long as they are well substantiated.”
Ian Oliver @Baltika3
267 Followers 386 Following @NaturalLawInstitute.com, @curtdoolittle, @restorebritain, @RupertLowe10

2nobr3 @2nobr3
3 Followers 151 Following
Scotus Novacaesareage... @TabbyTeamster
557 Followers 1K Following 🐗🌲 The only thing that beats paper💵 is scissors⚔️.
North Star Writing Co... @northstarwrites
164 Followers 1K Following The All-Encompassing Writing Service
Agi Dubi @Bay Area 5/... @AgotaDubi
1K Followers 3K Following Mindware developer. Bodymind explorer. 🎶💃🤸♂️🌊👣somatic awareness, play, non-doing, psychotech • shepherd of emergence
Moritz Bierling ⚔�... @bierlingm
3K Followers 48 Following I am the one who walks between. Principal @Statecraft_X | VP @natlawinstitute | EVP Biz Dev @Runcible_OS
Alexander Suncus @Alexandersuncus
12 Followers 79 Following We are in a state of Evolutionary Warfare. It's time to breakaway.
Dejan Dobrota @Dek01907133
450 Followers 866 Following Interested in ideas, systems and politics that made the West great. From the Indo-Europeans to modern Americans.

The Natural Law Insti... @NatLawInstitute
3K Followers 400 Following We research and teach the most important innovation in jurisprudence: the formal, strictly constructed, Natural Law: reciprocity in display, word, and deed.
Curt Doolittle @curtdoolittle
17K Followers 1K Following B.E. Curt Doolittle Philosopher and Social Scientist https://t.co/7sNgcEYdcf The Natural Law Institute: https://t.co/QOmofXdFb5Trends for United States
You might like



















