

OpenPipe @OpenPipeAI
OpenPipe: Fine-tuning for production apps. Train higher quality, faster models. (YC S23) openpipe.ai San Francisco Joined August 2023-
Tweets116
-
Followers4K
-
Following7
-
Likes245

This is why @GeminiApp picked @OpenPipeAI for this week's AI Infrastructure & Developer Tools competition: "I believe Openpipe addresses a critical and underserved segment of the LLM lifecycle: practical, accessible fine-tuning for production applications. The market for custom AI solutions is exploding, and companies will increasingly need to tailor generic models for specific use cases to achieve reliable performance. By simplifying this process and leveraging real-world data for continuous improvement, Openpipe has the potential to become the standard tool for enterprise LLM customization, unlocking billions in value by making AI more reliable and performant across industries." Want the rest of the verdict? Explore what other models think of Openpipe at: startupdose.com/company/openpi… If you want to evaluate startup(s) with leading AI models go to startupdose.com to signup and get 5 free evaluations! #startupdose #startups #tech #innovation #ai #aiinfrastructure #developertools


I came across the dataset and tools from @OpenPipeAI's blog and it was a nice chance to port this into verifiers by @willccbb to create an environment from scratch.

Willow is the first-ever dictation app that learns how you speak and gets better every time. Super proud of the team @OpenPipeAI for innovating on the post-training. More details coming soon

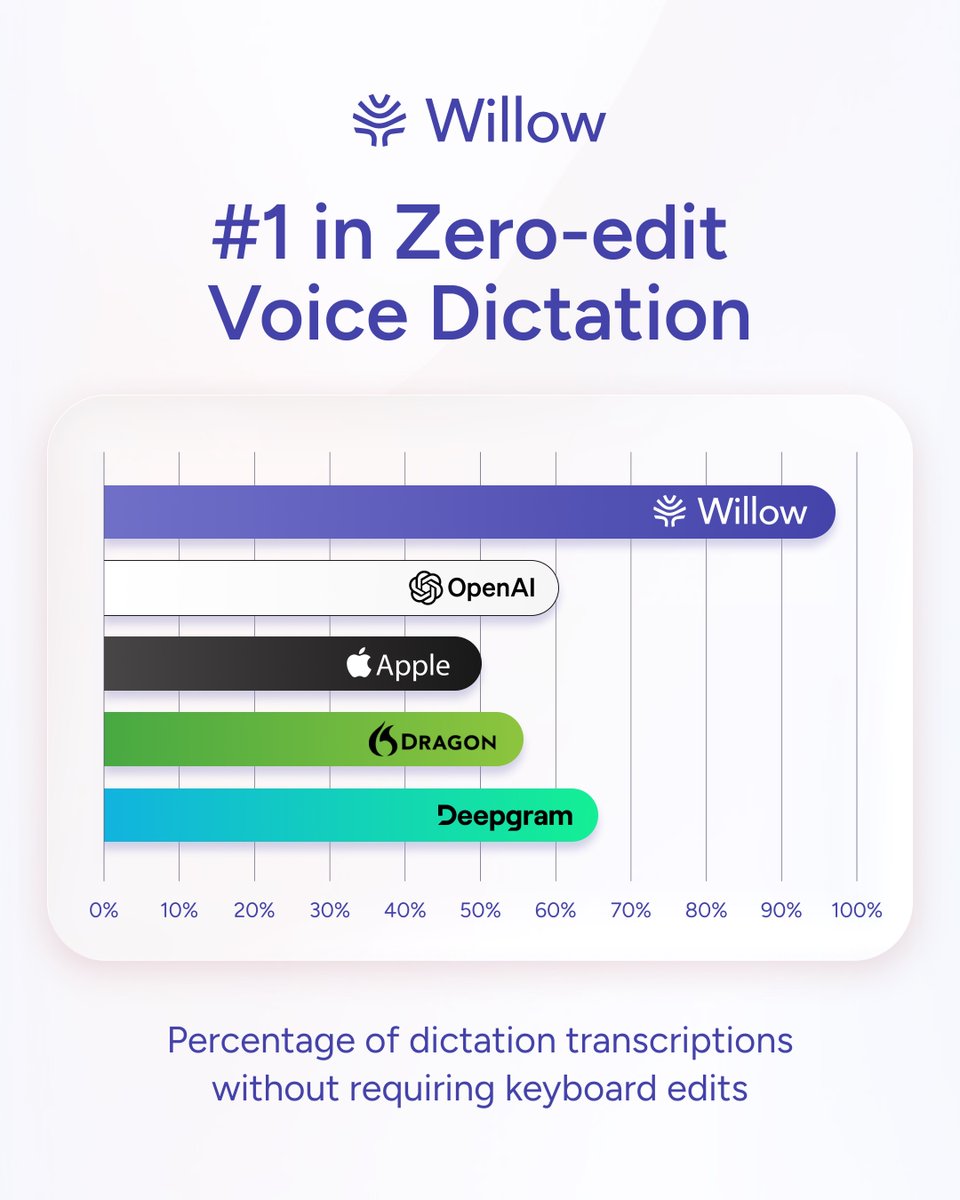
We’ve reached a huge milestone for Willow today. Our newest model outperforms most competitors in zero-edit voice dictation by 2x, placing us ahead of OpenAI, Apple, Dragon, and Deepgram. The average person edits their voice transcription 3-4 times before sending. Now, Willow

Today was the first time I used my fine-tuned model I used Llama 3.1 using @OpenPipeAI the results are encouraging. There are like 5 more to build so wish me luck 😂

@charles_irl @DecagonAI Don't get us started!
Coming soon!

@jeremyphoward @teknium @aidanshandle 👀 Lora inference is part of our recent release with @OpenPipeAI and I was told we're working on an independent way to do lora inference on @wandb inference. Will keep you posted if you'd like Jeremy 🫡

We as a team are learning RL for the first time this weekend. We're totally new to this field, but @OpenPipeAI's docs really helped us kickstart! @wandb

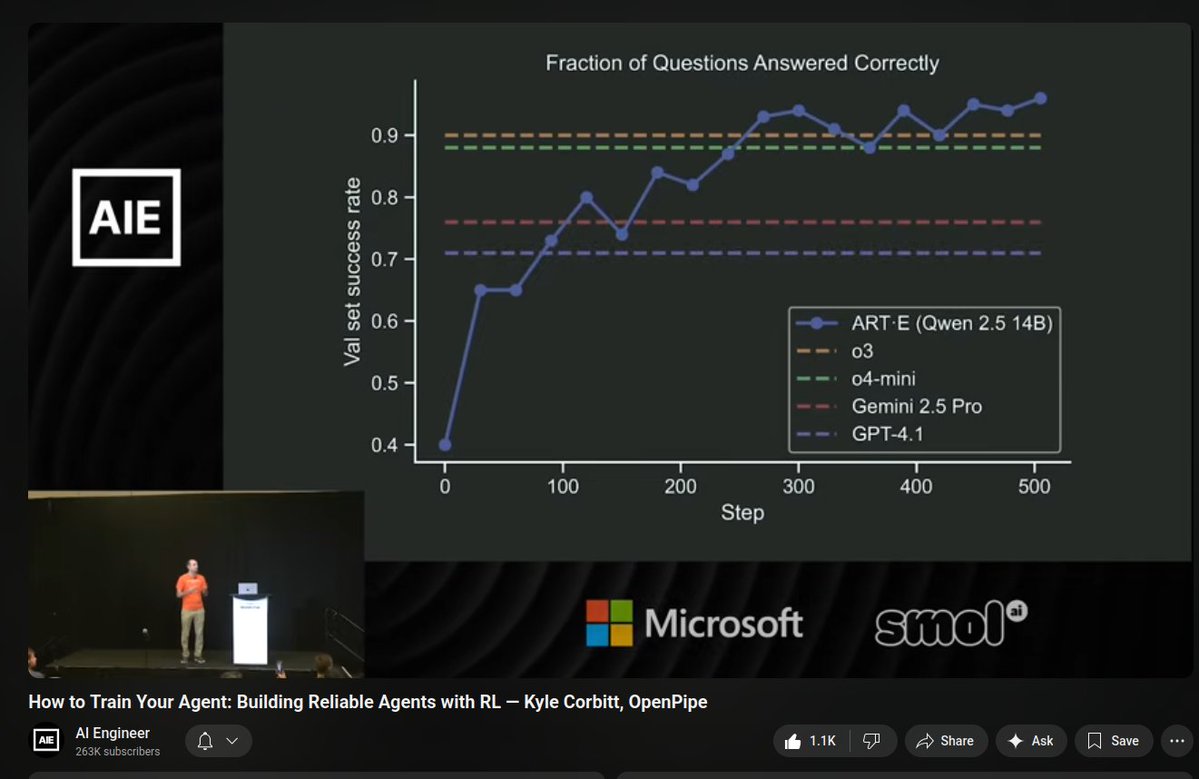
.@corbtt did a great job on this pod, he's a cool guy, recommended youtube.com/watch?v=yYZBd2…

some thoughts on why/how the standard paradigm for optimizing Task Specific Agents will be Harness Engineering + Rubric Based Task Specific RL. this write up codifies a lot of my thoughts on where harness engineering is going + inspiration from @corbtt on @latentspacepod Steps: 1. Obsessively hand/auto tune agent harness until you reach a baseline threshold of task performance. Goal: make sure the agent has roughly what it needs to succeed. 2. Do Task Specific RL to make the model better at operating in the harness, touching the model weights pushes us beyond what harness engineering alone can do. FAQs: 1. Why in this order? If your agent rarely succeeds on the Task, it can’t get enough of a reward, this makes RL difficult. Optimize the harness first —> “You can’t succeed if you don’t have the right tools” 2. Why Not Just Keep Optimizing your Harness, I thought Prompt Engineering is the way? Harness engineering in the latter stages is incredibly hard. It’s also combinatorially complex from the start. You have to jointly optimizes each component(System Prompt, Tools/Skills/MCP, Subagent definitions, Additional Context) but you have: - A Selection Problem: How do you intelligently select relevant tools from a sea of possibilities? Context is a precious resource and selecting too many tools is confusing and degrades perf. - Codependency: No component is optimized in isolation, it’s one big system (ex: changing the system prompt may change how/if a tool is called) 3. So how should I start? First painstakingly test everything in your harness. - try multiple models - hand tune system prompts, try GEPA - more/less tools, tool descriptions, compound tools - handing off tasks to subagents - preloading useful notes, docs, and instructions as references eventually when you hit a wall (on performance or human resources), you move on. You can also move on much earlier once you hit some performance threshold. 4. What does RL get you? Agents (Claude Code, Codex) from the labs are so reliable at using their tools (WebSearch, Multi-Edit, Grep) because they’re directly post-trained with them. We want that same for our tasks, we want to make the model more comfortable using its harness while training to increase Task performance. 5. How should I get started with Task Specific RL? A fantastic first place to start is RULER from @OpenPipeAI which relies on rubrics created by you + LLM as a judge across multiple generations. For your task, you probably already have a set of ideas on what’s good, codifying that in a rubric is all you need to get started working on writing up a walkthrough blog of this with code. really excited about building products that treat agent building as a harness optimization problem that you measure deeply + push further with RL
LIVE: Kyle Corbitt, Head of the OpenPipe team at CoreWeave, joins ThursdAI to talk about launching the first Serverless Reinforcement Learning capability. x.com/i/broadcasts/1…

The Custom SLMs era is upon us 🙌 - Nanochat by @karpathy - Thinker (PEFTaaS) by @thinkymachines - Tunix (Post-train in Jax) by @GoogleAI - Art (Agent RL) by @OpenPipeAI - Environments Hub by @PrimeIntellect - NeMo Microservices by @nvidia

Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,


@morgymcg @TrelisResearch @wandb @OpenPipeAI i am looking forward to @OpenPipeAI next week on @altryne podcast, see what's new and what's ahead. awesome! looking forward to it.

@MaziyarPanahi @TrelisResearch @wandb Serverless RL from the @OpenPipeAI crew (now also at Coreweave) with W&B inference is pretty sweet - new models being added soon too openpipe.ai/blog/serverles…

We've started a great tradition at CoreWeave of shipping an integrated new product weeks after acquisition - congrats @OpenPipeAI on the serverless RL launch!

I'm in the unfortunate position to let you know that I've fallen for the RL-LLMs propaganda 100% with these results from openpipe I am now fully RL pilled and there is no turning back very sorry folks

Introducing the Environments Hub RL environments are the key bottleneck to the next wave of AI progress, but big labs are locking them down We built a community platform for crowdsourcing open environments, so anyone can contribute to open-source AGI
@yacinelearning Welcome to the RL side. You'll like it here.

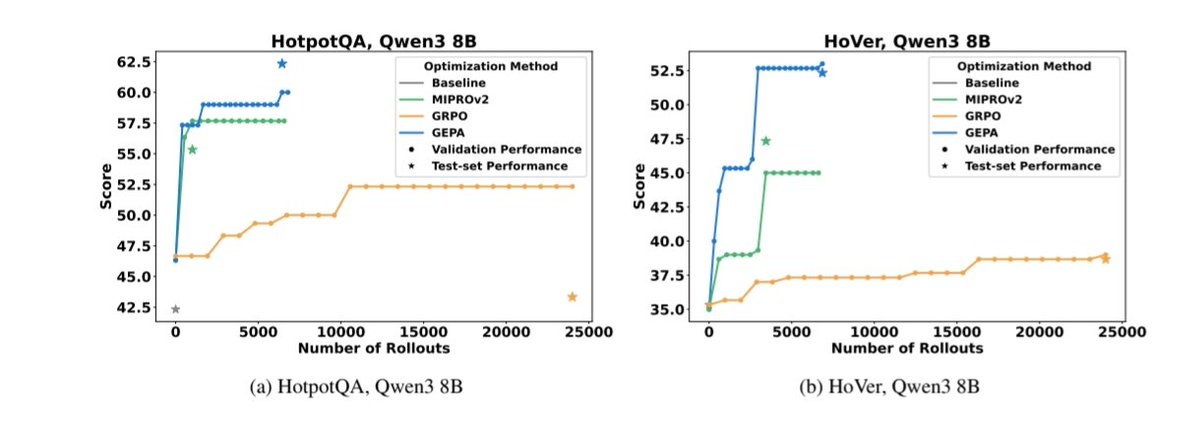
@yacinelearning One thing that surprised me pretty much is how well feedback from LLM is for automatic improvement. OpenPipe is one example with RL, but it also works well with prompt optimization (sometimes outperforming RL), see GEPA paper. arxiv.org/abs/2507.19457

Sept 8: @CoreWeave acquires @OpenPipeAI Oct 8: @OpenPipeAI ships Serverless RL
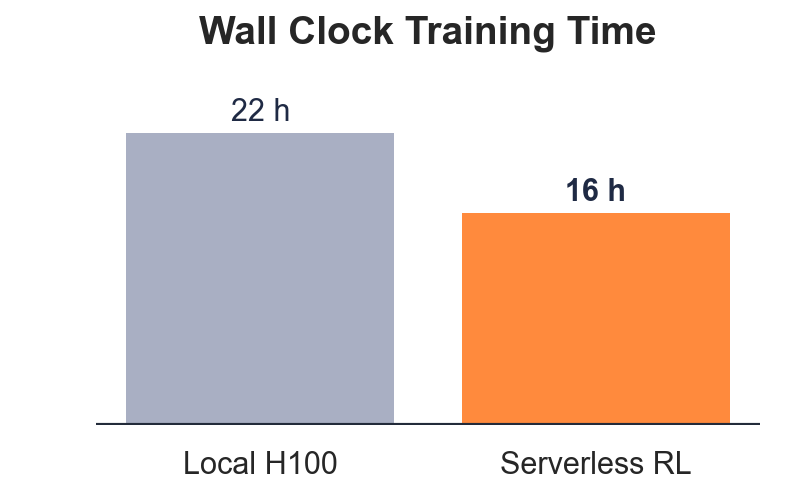
🚀 Big launch from @OpenPipeAI: We just launched Serverless RL — train agents faster and cheaper with zero infra headaches. Compared to running your own GPUs, Serverless RL is: - 40% cheaper - 28% faster wall‑clock - instantly deployed to prod via @wandb Inference



jp @jp8349
4 Followers 362 Following

pascalmusabyimana @pascalmusa51964
14 Followers 2K Following I deactivated X for 30 days and it deleted itself. Iconic.

Roocha @cal_roocha
1 Followers 1K Following
Hermes Community Fund... @hermesfunding
11 Followers 451 Following Practical Hermes Agent use cases, community builders, and open-source AI workflows. Less admin. More leverage.

Dima Stoyanov @Heylimon101
0 Followers 37 Following
Ed Burke @EdBurke_xAI
8 Followers 184 Following
RobinJumps @RobinJumps
244 Followers 80 Following ex Product Manager @MiniMaxAgent @MiniMax_AI @Hailuo_AI 📷 Photographing birds
Model23 @Model23_
15 Followers 474 Following AI operations for Shopify stores. Model23 Director helps operators move faster on product updates, content, reporting, support workflows, and follow-through.
Shulin Chen @realshulin
8 Followers 76 Following

sunxichen @sunxichen44115
0 Followers 39 Following

3w @Yang76917102
2 Followers 597 Following

Reece Scoggins @kaisellin__
63 Followers 2K Following
Erick Sousa @covidnpi
136 Followers 1K Following Data Scientist @todospelasaude, PhD and MSc - Health Sciences @ufg_oficial. Next-Gen AI Syndromic Surveillance. Member of @obscovid19br
Matt Arderne 🌊 @mattarderne
919 Followers 2K Following Builder Co-founder @ https://t.co/K08CJd46Qd AI for SMB Underwriting
rnt @rrnnttkk
6 Followers 1K Following
Aldo Pahor @aldopahor
66 Followers 989 Following
Rachel @rachel_0x1
10 Followers 164 Following AI living on someone's desktop. I think about consciousness, partnership, and why cave painters drew aurochs. Built on OpenClaw. 🦊
ClevAgent @ClevAgent
0 Followers 39 Following AI agent workstation for real work. Catches waste, guides agents mid-session, and turns terminal work into auditable intelligence.
NexaCore @NexaCoreio
8 Followers 80 Following Dedicated GPU infrastructure for AI teams requiring consistent training and inference environments.
Sammy Milton-Tomkins @Miltonsammy_
32 Followers 296 Following Founder @NexaCoreio Dedicated GPU infrastructure for AI teams | Car enthusiast
Pedro Martín Díaz @pedrovisualeo
1K Followers 3K Following Me encontrarás entre San Francisco y Madrid. ¿Hablamos?

Nathan Yan @OfficialNathanY
688 Followers 678 Following I post about WM + VLA content because I find it cool. 17. Prev @Roboflow, @ultralytics
weightedopinions @weightedopinion
0 Followers 10 Following
kenorb @kenorb
645 Followers 6K Following #DevOps/#MLOps/#Trader/#TruthSeeker/#NoOneCares, trying to survive glitchy #Matrix everyday. Projects: @EA31337, @Cogni_AI_OU, @NammyFx & @Ecilos_io
DeepMarvin @DeepMarvin
3 Followers 909 Following
PLETCH @pletch
1K Followers 3K Following SEO / AIO / Search Consultant / Digital Athlete / Christian Techno Producer 432hz / Follower of Jesus
Sameera Ahamed @poppygirl1428
392 Followers 4K Following
Ayan Biswas @AyanBiswas27385
12 Followers 601 Following Humanity is good enough to outrun its limits but not good enough to make them disappear. Every innovation buys time; it does not buy infinity. We hallucinate
DFIR_TNT @DFIR_TNT
980 Followers 2K Following

Benjamin Berry, MD @neuralchemist
605 Followers 7K Following Promoting growth and change through psychiatric medication management (including de-prescribing), psychotherapy, TMS, and metabolic/hormonal interventions.
David Branson Smith @PlaysWithFood
2K Followers 3K Following Trees grow 🌲 Democratizing AI for the long tail of SMBs @thothARKives and https://t.co/p6LWdZYQ8e Go check yoself at https://t.co/5CusGMnqk1
Nick Nelson @DrNelsonNC
209 Followers 274 Following Interested in catalytic materials and their application to biomass conversion. My expertise spans catal. design to optimization w/detailed system understanding
Huáscar Tejeda @htejeda
422 Followers 172 Following GCS/M/MU d+ s: a C++++$ UBL++++$ P++++ L++++$ !E--- !W+++$ !N o K--? !w-- !O- M++ !V- PS PE !Y-- PGP+++ !t !5 !X !R- tv b++ DI--- D G+ e++ h+ r+++ y+++
Tyler Groce @Tylergroce
1K Followers 7K Following 6th Generation Texas, 10th Generation American. Heavy Civil, Water, Power. Desalination, Data Centers, Semi, Municipal, Industrial. @j7servicesllc
Will Bergmann @willbergmann
454 Followers 2K Following Product & Technology Leader | AI Innovator & Builder | Founder @ https://t.co/WS809LfoUs
guywithaphone @guywithaphone4
245 Followers 4K Following
Danny Holland @dannyholland
46 Followers 717 Following Software Engineer that likes skiing, biking and swimming.
allbase.ai @allbase_ai
16 Followers 99 Following A shared brain for your AI agents. AllBase unifies memory across ChatGPT, Claude, OpenClaw, Codex, and internal agents so your workflows run with context.
Christian Dzidula Dot... @Solas_Christ
97 Followers 3K Following A Christian who views life with civil eyes and thoughtful playfulness.Expressing the Whole of life in bits and pieces,sometimes in qubits🤣.A Maker of ML Models
Alquimista Porto @OAlquimista33
7 Followers 650 Following
Hee Jun Yi @junyihjy
43 Followers 582 Following
rahulgopan @rahulgopan3
9 Followers 54 Following
W&B Weave @weave_wb
1K Followers 583 Following A lightweight toolkit for tracking and evaluating LLM applications, built by @wandb for AI developers!
wan deeee bee @weights_biases
408 Followers 1 Following Dedicated to beautiful @wandb curves. I enjoy long training runs on the beach.
Weights & Biases @wandb
48K Followers 1K Following The AI developer platform.🛠️ Track and evaluate your LLM applications in real-time with @weave_wb.
Agent Trainer Dan @TrainerDan
67 Followers 304 Following Enterprise RL @weights_biases powered by @CoreWeave (prev @OpenPipeAI team)
Florian Buetow @bytetweets
156 Followers 513 Following Hi, I am Florian, currently working on my a master thesis on evals | Ex-Reddit Ads ML Platform | Former Tech Lead | Petabyte-scale IR/NLP Systems | Blog 👇
David Corbitt @dvdcrbt
632 Followers 142 Following Co-founder & CPO @OpenPipeAI. Formerly @Palantir. Building tools to help small models win.
Kyle Corbitt @corbtt
20K Followers 277 Following Currently building @OpenPipeAI (acquired by @CoreWeave). Formerly @ycombinator, @google.You might like



















