

Jonathan Heek @JonathanHeek
Joined August 2019-
Tweets17
-
Followers521
-
Following5
-
Likes19
5/5 Results on ImageNet-512: competitive FID of 1.4 with high reconstruction quality (PSNR: 25.7). On Kinetics-600 video generation: we set a new state-of-the-art FVD of 1.3. Even our small model hits 1.7 FVD. Finally, we scale to text-to-image with strong perceptual quality.
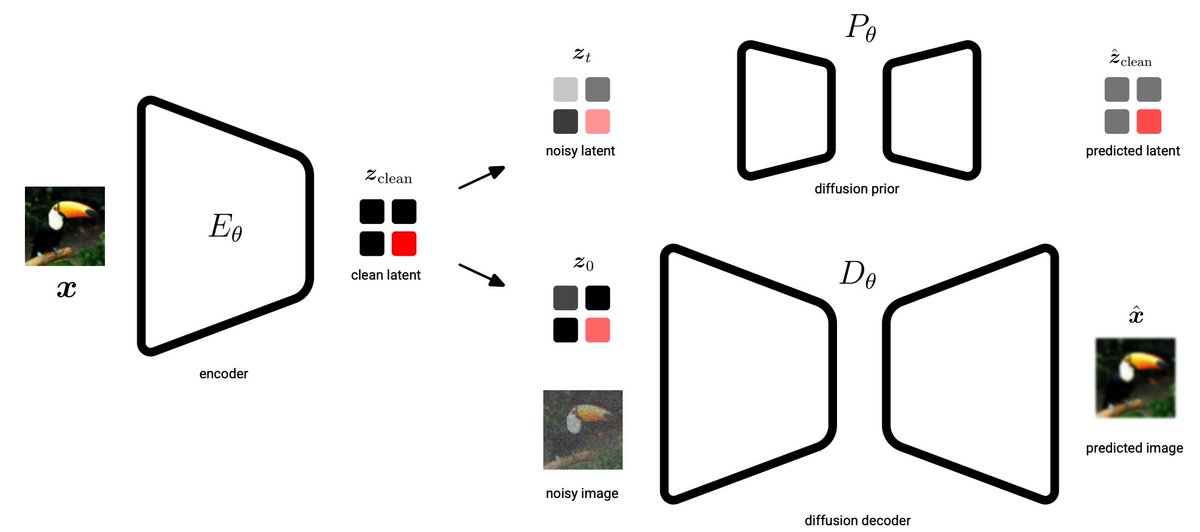
4/6 This gives you a simple knob to control the reconstruction vs. modeling trade-off. Higher bitrate = better reconstruction but harder to model. Lower bitrate = easier to model but you lose fine details.
1/6 Introducing Unified Latents: what if your diffusion model's latents were measured in bits? Instead of relying on dimensionality reduction, we learn a latent AE with explicit bitrate control. Paper: arxiv.org/abs/2602.17270 @emiel_hoogeboom, @TimSalimans

Is pixel diffusion passé? In 'Simpler Diffusion' (arxiv.org/abs/2410.19324) , we achieve 1.5 FID on ImageNet512, and SOTA on 128x128 and 256x256. We ablated out a lot of complexity, making it truly 'simpler'. w/ @tejmensink @JonathanHeek @KayLamerigts @RuiqiGao @TimSalimans


🚀 Interested in time series generation?⏲️Excited to share my @GoogleDeepMind Amsterdam student researcher project: Rolling Diffusion Models! arxiv.org/abs/2402.09470 (to appear at ICML 2024) Thanks for the great collaboration @emiel_hoogeboom, @JonathanHeek, @TimSalimans! 🧵1/4
We have a new distillation method that actually *improves* upon its teacher. Moment Matching distillation (arxiv.org/abs/2406.04103) creates fast stochastic samplers by matching data expectations between teacher and student. Work with @emiel_hoogeboom @JonathanHeek @tejmensin. 1/4

Fast sampling with 'Multistep Consistency Models': We get 1.6 FID on Imagenet64 in 4 steps and scale text-to-image models, generating 256x256 images with 16 steps. Guess which row is distilled? With @emiel_hoogeboom @TimSalimans Arxiv: arxiv.org/abs/2403.06807

If diffusion models are so great, why do they require modifications to work well? Like latent diffusion and superres diffusion? Introducing "simple diffusion": a single straightforward diffusion model for high res images (arxiv.org/abs/2301.11093) . w/ @JonathanHeek @TimSalimans


🥳 It is now super easy to fine-tune EfficientNet in FLAX! We open sourced a FLAX version of all officials EfficientNet checkpoints as a by product of our last paper: github.com/google-researc…

JAX on Cloud TPUs is getting a big upgrade! Come to our NeurIPS demo Tue. Dec. 8 at 11AM PT/19 GMT to see it in action, plus catch a sneak peek of a new Flax-based library for language research on TPU pods. Link: neurips.cc/ExpoConference… (neurips.cc/Register2 is still open!)


I’d like to share the new JAX/Flax PixelCNN++ (using new Flax ‘linen’ API github.com/google/flax/tr…), a performant baseline AR image model, built as part of my internship at Google Brain Amsterdam. github.com/google/flax/tr…. 👇

@LazyOp @NalKalchbrenner Thanks for spotting that. You are correct, those terms are missing from the pseudo-code. I will make sure that this gets fixed in the revision.
@duane_rocks @avitaloliver @DeepSpiker Actually it's both. There's uncertainty in the model outputs and uncertainty about the model parameters. Sampling is used to marginalize over the uncertainty in the model parameters to obtain predictive uncertainty.
@goodfellow_ian @NalKalchbrenner There's definitely reason to believe that a "Bayesian discriminator" will result in a better behaved estimate of D*. The predictions will be less saturated potentially resulting in a better signal for the generator. An ensemble of discriminators could improve robustness further.
Announcing exciting progress in Bayesian deep learning: the new ATMC sampler achieves first of its kind Bayesian inference results on ImageNet Check out the results and the paper 👇 Heek et al: arxiv.org/abs/1908.03491


Gggrrraa @Gggrrraa11367
9 Followers 328 Following
Deressa Wodajo @DeressaWodajo
122 Followers 906 Following PhD student at @IDLabResearch, @ugent. Deep Learning.
David Wessels @Dafidofff
425 Followers 305 Following PhD candidate w/ @erikjbekkers & @egavves interested in Geometric Deep Learning and Generative Modelling at @AmlabUva
sanj @splicewiring
62 Followers 189 Following working on AI to get more biological insights, bias for action, AI PhD, lived in 4 continents/20 cities!
Wouter Kool @wouter_kool
288 Followers 280 Following PhD in Machine Learning & Optimization from University of Amsterdam
Yixin Huang @YixinH57903
3 Followers 74 Following

Tommaso Martorella @_tommymarto_
24 Followers 170 Following ELLIS PhD student in generative ML @ CompVis (Ommer Lab), @LMU_Muenchen, @ELLISforEurope | prev. @epfl_en Excellence Fellow

Louis @Louis9687221579
75 Followers 3K Following Mainline Economics | Idea page | ramblings of a schizo
Mike Gonzalez @mgonzalez
682 Followers 2K Following Founder @benchmarkAIapp. Previously co-founder/CEO https://t.co/OLGUUWRMJJ (acquired by @paylocity), VP @zenefits, PM @facebook, and helped US gov't at OPM
oriol @oriolaseques
176 Followers 277 Following
Jan @itsjanfranco
72 Followers 887 Following
Nick @ntrlsk
1K Followers 4K Following investing @hiFramework. former rates/commodities vol trader @DRWTrading. Tweets are my views and not personal advice. May have positions in assets discussed.
Zac Dean is now in hy... @zac___who
167 Followers 7K Following I build apps to make your life 10% less stressful. @WhodataInc
Anh Nguyen @NguynTu24128917
1K Followers 7K Following Member of Technical Staff at Project Prometheus ex Foundation Model @Apple, Phi @MSFTResearch

Fatih⏩⤴️ @taskinfatih
618 Followers 7K Following Lover of all novel and hard concepts: especially machine learning and systems theory
Xingjian Bai @SimulatedAnneal
532 Followers 525 Following Ph.D. student at @MITEECS. Previous RA at @Oxford_VGG.
Chris Offner @chrisoffner3d
4K Followers 3K Following 3D computer vision, spatial AI, and synthetic data @Google XR. visual computing, machine learning, robot perception
Jiseob Kim @__jkim__
2 Followers 217 Following
toe_of_frege @eye_of_newton
17 Followers 1K Following
Viacheslav Meshchanin... @Viacheslav91112
124 Followers 188 Following Research scientist @bayesgroup | Ph.D. student at @constructor_uni Developing diffusion models for language & biological sequences.
Niklas Rindtorff @Niklas_TR
3K Followers 4K Following PhD student at AITHYRA with @AlexanderTong7. Feedback: https://t.co/QSPQ7sdUp2
Alberto Tono @albertotono3
1K Followers 986 Following Applied Scientist @adobe l PhD Candidate @Stanford | Founder @CDInstitut | Ex-SR @googledeepmind
Antonio Franca @antoniofrancaib
419 Followers 580 Following PhD ML @ AITHYRA • Generative models for biophysics

Changqing Fu @evergreencqfu
82 Followers 848 Following PhD student in Computer Vision and Machine Learning in Univ. Paris 9 - PSL
Yang Yue @YangYue97847321
33 Followers 286 Following
Gaëtan Hadjeres @gaetan_hadjeres
539 Followers 559 Following Member of Technical Staff at Black Forest Labs. Studied music composition at Paris Conservatoire. Likes neural networks and music.


ꙮ @mechsodus
2 Followers 349 Following
Nate @NateWBradford
260 Followers 2K Following
Alexi Gladstone @AlexiGlad
3K Followers 660 Following PhD @ UIUC and doing stuff @flappyairplanes. Working on EBTs/EBMs, World Models, Reasoning. Prev @Meta, @PalantirTech, @UVA
visionawry @awryvision
5 Followers 1K Following
Florian @fses91
110 Followers 966 Following


dadabots @dadabots
11K Followers 9K Following ∿ Music hackers. Algoraves. Inventing, playing. Neural synthesis. 24/7 ai death metal. Stable Audio team. Open models. Mischief @harmonai_org @artblocks
XK @carlons_macer
5 Followers 118 Following
Rex Cheng @hkchengrex
343 Followers 522 Following RS @LumaLabsAI | PhD @IllinoisCDS | prev Intern @metaai, @SonyAI_global, @KaiberAI, @AdobeResearch | Kurisu #1 fan
dominik @dodo_zwitschert
132 Followers 809 Following
Tuan Le @tuanle618
351 Followers 658 Following Machine Learning Researcher @Pfizer. PhD CS with background in generative modeling, computational chemistry and graph representation learning.
Yifei Wang @WangYw251
157 Followers 163 Following Research #representationlearning #diffusion; PhD student @RiceUniversity; Visiting student @JohnsHopkins; Prev @PKU1898
keshav Kant @keshavvkant
375 Followers 7K Following A fractal mind, trying to find self similarities in the world. MSc biology'24 @AshokaUniv
Akash @akashaapz
14 Followers 983 Following
Natnael Daba @DabaNatnael
4 Followers 451 Following

Desh Raj @rdesh26
4K Followers 2K Following Speech + LLMs @nvidia | Previously: @Meta MSL, @jhuclsp, @IITGuwahati

Emiel Hoogeboom @emiel_hoogeboom
3K Followers 196 Following MTS at Anthropic. Previously Google Deepmind, PhD with @wellingmax at University of Amsterdam, Qualcomm Internship.
ML Limericks @MLimericks
2K Followers 44 Following Limericks about machine learning. Originally by @fhuszar
Boyan Slat @BoyanSlat
199K Followers 207 Following Studied aerospace engineering, becomes a cleaner. Founder/CEO @TheOceanCleanup
Nal @nalkalc
36K Followers 269 Following Angel investor. Ex Researcher in Deep Learning @GoogleDeepMind. Co-creator @GoogleAI Brain Amsterdam, Ex original @DeepMind, Edu at Oxford, UvA and Stanford.You might like













