

BigCode @BigCodeProject
Open and responsible research and development of large language models for code. #BigCodeProject run by @huggingface + @ServiceNowRSRCH bigcode-project.org Joined August 2022-
Tweets271
-
Followers9K
-
Following3
-
Likes226

It’s so much fun working with the other 39 community members on this project! Start to try out various frontier models in BigCodeArena today.
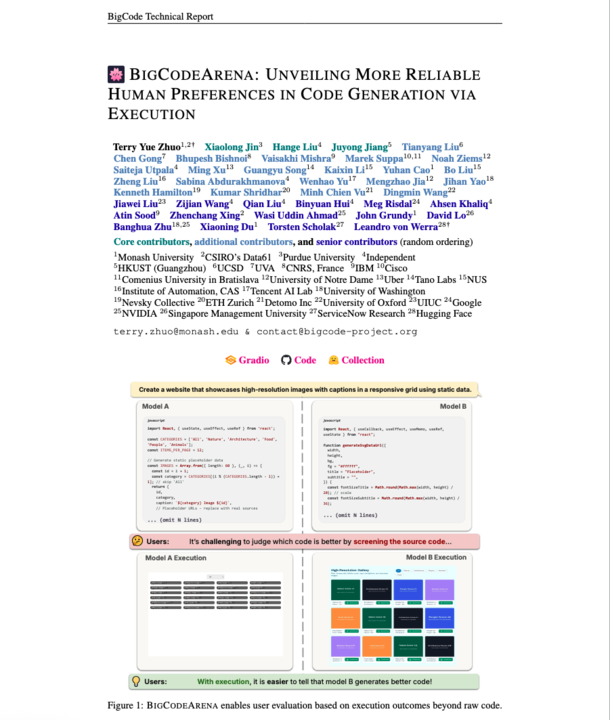
Introducing BigCodeArena, a human-in-the-loop platform for evaluating code through execution. Unlike current open evaluation platforms that collect human preferences on text, it enables interaction with runnable code to assess functionality and quality across any language.

- For more details, please check out the blog: huggingface.co/blog/bigcode/a… - Try recent LLMs (e.g., Qwen3 series and DeepSeek-V3.2) on BigCodeArena now: huggingface.co/spaces/bigcode… - Paper Link: drive.google.com/file/d/1gt5Ws0… - GitHub: github.com/bigcode-projec…
BigCodeArena cannot be built without the support of the BigCode community. We are grateful for the huge credits provided by the @e2b team. We thank @hyperbolic_labs, @nvidia, and @Alibaba_Qwen for providing the model inference endpoints.
Introducing BigCodeArena, a human-in-the-loop platform for evaluating code through execution. Unlike current open evaluation platforms that collect human preferences on text, it enables interaction with runnable code to assess functionality and quality across any language.
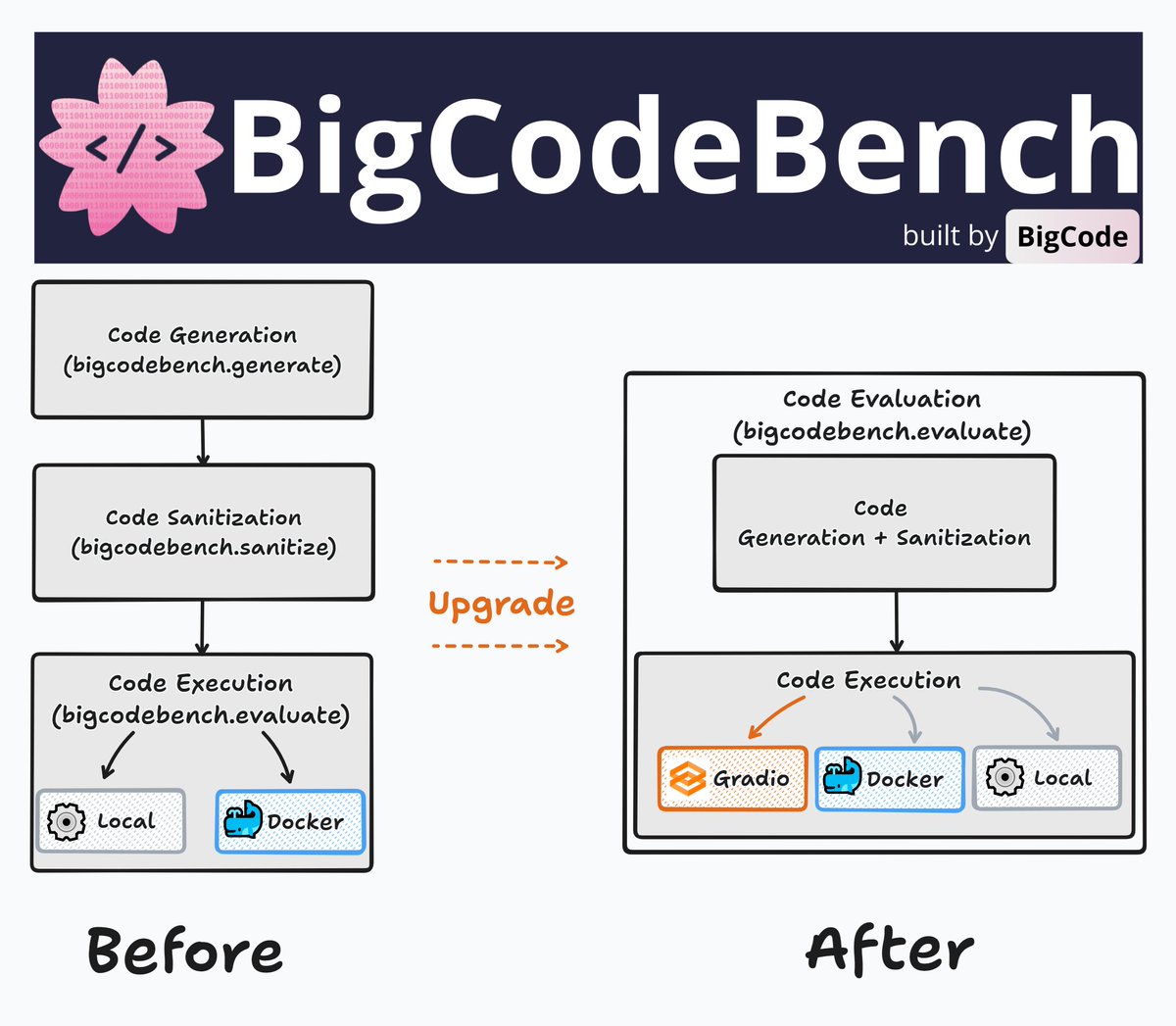
BigCodeBench @BigCodeProject evaluation framework has been fully upgraded! Just pip install -U bigcodebench With v0.2.0, it's now much easier to use compared to the previous v0.1.* versions. The new version adopts the @Gradio Client API interface from @huggingface Spaces by default, w/o the need for local environment setup, and can be replaced with a custom API if desired. Moreover, the latest version no longer requires running separate commands for each stage (like generate, sanitize, and evaluate), significantly simplifying the workflow. The new version also features Batch Inference — running the LLMs on the BigCodeBench-Full set now takes under 5mins for generation and execution! BTW, the benchmark data has been updated to v0.1.2, improving task instructions and test examples. Some of the updates in this release were inspired by EvalPlus @JiaweiLiu_ . A big thank you for the continued maintenance of EvalPlus and the strong support for BigCodeBench 🤗

Evaluating LM agents has come a long way since gpt-4 released in March of 2023. We now have SWE-Bench, (Visual) Web Arena, and other evaluations that tell us a lot about how the best models + architectures do on hard and important tasks. There's still lots to do, though 🧵
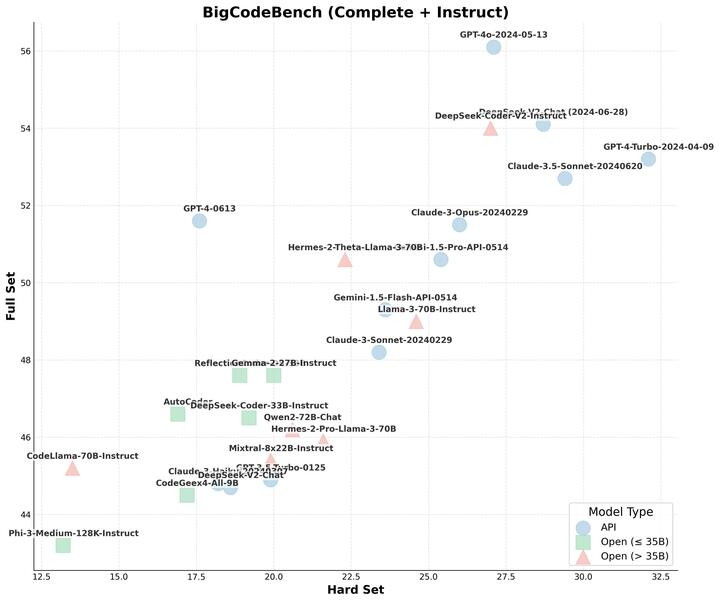
People may think BigCodeBench @BigCodeProject is nothing more than a straightforward coding benchmark, but it is not. BigCodeBench is a rigorous testbed for LLM agents using code to solve complex and practical challenges. Each task demands significant reasoning capabilities for selecting appropriate library APIs and logically connecting them to craft a program. Rather than merely providing high-level instructions, each task comes with detailed requirements to evaluate the model's ability to adhere to all aspects. While language models typically perform well on short and simple tasks, they often struggle with longer and more complex problems (e.g., BigCodeBench-Hard). A model needs to perform well on BigCodeBench before it can be used for agentic software development.

By popular demand, I have released the StarCoder2 code documentation dataset, please check it out ⬇️ hf.co/datasets/Sivil…

This work will appear at OOPSLA 2024. New since last year: the StarCoder2 LLM from @BigCodeProject uses MultiPL-T as part of its pretraining corpus.
LLMs are great at programming tasks... for Python and other very popular PLs. But, they are often unimpressive at artisanal PLs, like OCaml or Racket. We've come up with a way to significantly boost LLM performance of on low-resource languages. If you care about them, read on!
Today, we are happy to announce the beta mode of real-time Code Execution for BigCodeBench @BigCodeProject, which has been integrated into our Hugging Face leaderboard. We understand that setting up a dependency-based execution environment can be cumbersome, even with the built-in Docker image and Dockerfile. To make the evaluation process more reproducible, we've built an interactive environment for you, with guidance from the @Gradio team! (Special thanks to @evilpingwin 🤗) Please note: (1) The execution process might be slightly slower than what you experience on a local machine, as we are using the basic CPU option. There are some compatibility issues with the upgraded CPU environment, and we are currently exploring solutions. (2) Four tasks in the full set require some tricky setup, which has resulted in a pass rate of 99.6%. We will work to fix these in the next iterations :)

In the past few months, we’ve seen SOTA LLMs saturating basic coding benchmarks with short and simplified coding tasks. It's time to enter the next stage of coding challenge under comprehensive and realistic scenarios! -- Here comes BigCodeBench, benchmarking LLMs on solving

Releasing BigCodeBench-Hard: a subset of more challenging and user-facing tasks. BigCodeBench-Hard provides more accurate model performance evaluations and we also investigate some recent model updates. Read more: huggingface.co/blog/terryyz/b… Leaderboard: huggingface.co/spaces/bigcode…

BigCodeBench dataset🌸 Use it as inspiration when building your Generative AI evaluations. BigCodeBench h/t: @BigCodeProject @terryyuezhuo @lvwerra @clefourrier @huggingface (to name just a few of the people involved)
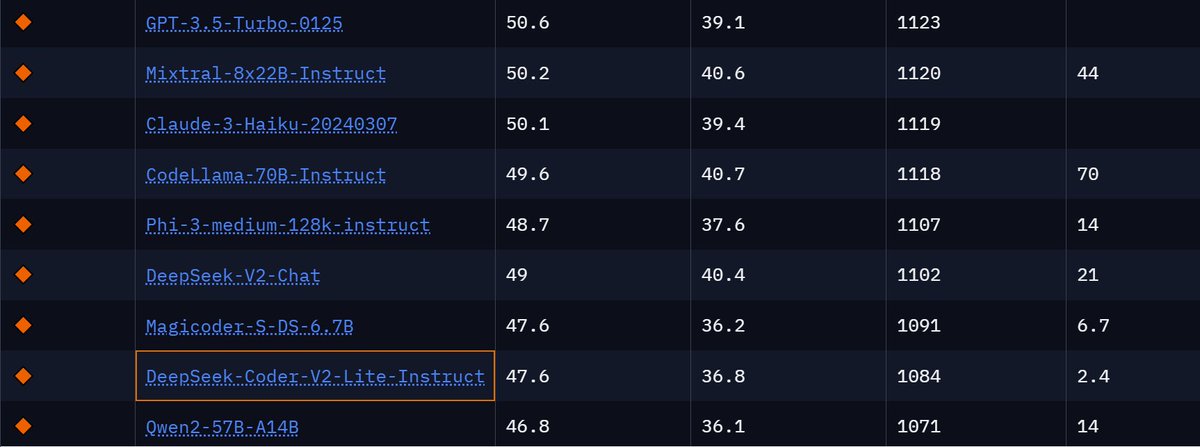
Ppl are curious about the performance of DeepSeek-Coder-V2-Lite on BigCodeBench. We've added its results, along with a few other models, to the leaderboard! huggingface.co/spaces/bigcode… DeepSeek-Coder-V2-Lite-Instruct is a beast indeed, similar to Magicoder-S-DS-6.7B, but with only 2.4B activated parameters! 🤯 We also update all the code generation results here: github.com/bigcode-projec… Feel free to submit a PR if you want to see other models on BigCodeBench 🤗github.com/bigcode-projec…
Introducing 🌸BigCodeBench: Benchmarking Large Language Models on Solving Practical and Challenging Programming Tasks! BigCodeBench goes beyond simple evals like HumanEval and MBPP and tests LLMs on more realistic and challenging coding tasks.

It is time to deprecate HumanEval! 🧑🏻💻 @BigCodeProject just released BigCodeBench, a new benchmark to evaluate LLMs on challenging and complex coding tasks focused on realistic, function-level tasks that require the use of diverse libraries and complex reasoning! 👀 🧩 Contains 1,140 tasks with 5.6 test cases each, covering 139 libraries in Python. 📊 Uses Pass@1 with greedy decoding and Elo rating for comprehensive evaluation. 🏆 Best model is GPT-4o 61.1%, followed by DeepSeek-Coder-V2. 🥈 Best open Model is DeepSeek-Coder-V2 with 59.7%, better than Claude 3 Opus or Gemini. 👥 Tasks are created in a three-stage process, including synthetic data generation and cross-validation by humans. 🧱 Evaluation framework and Docker images available for easy reproduction 🔜 Plans to extend to multilingualism. Blog: hf.co/blog/leaderboa… Leaderboard: huggingface.co/spaces/bigcode… Code: github.com/bigcode-projec…

In the past few months, we’ve seen SOTA LLMs saturating basic coding benchmarks with short and simplified coding tasks. It's time to enter the next stage of coding challenge under comprehensive and realistic scenarios! -- Here comes BigCodeBench, benchmarking LLMs on solving practical and challenging programming tasks! So, can LLMs solve these tasks? - Not yet! 🏆 Pass@1: Humans ace 97%, GPT-4o only hits 50-60%, but DeepSeek-Coder-V2 is tighy at its heels! Check out our leaderboard, data, code, and paper: bigcode-bench.github.io 1/🧵
Introducing 🌸BigCodeBench: Benchmarking Large Language Models on Solving Practical and Challenging Programming Tasks! BigCodeBench goes beyond simple evals like HumanEval and MBPP and tests LLMs on more realistic and challenging coding tasks.
We release leaderboard, dataset, code, and paper: - 🤓 Blog: hf.co/blog/leaderboa… - 🌐 Website: bigcode-bench.github.io - 🏆 Leaderboard: huggingface.co/spaces/bigcode… - 📚 Dataset: huggingface.co/datasets/bigco… - 🛠️ Code: github.com/bigcode-projec… - 📄 Paper: github.com/bigcode-bench/…
BigCodeBench contains 1,140 function-level tasks to challenge LLMs to follow instructions and compose multiple function calls as tools from 139 Python libraries. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%.
Introducing 🌸BigCodeBench: Benchmarking Large Language Models on Solving Practical and Challenging Programming Tasks! BigCodeBench goes beyond simple evals like HumanEval and MBPP and tests LLMs on more realistic and challenging coding tasks.

Jim Fan @DrJimFan
439K Followers 3K Following NVIDIA Director of Robotics & Distinguished Scientist. Co-Lead of GEAR lab. Solving Physical AGI, one motor at a time. Stanford Ph.D. OpenAI's 1st intern.
Hugging Face @huggingface
701K Followers 222 Following The AI community building the future. https://t.co/TpiXQMQ9rZ
clem 🤗 @ClementDelangue
359K Followers 5K Following Co-founder & CEO @HuggingFace 🤗, the open and collaborative platform for AI builders
Omar Sanseviero @osanseviero
70K Followers 3K Following MTS at @GoogleDeepMind Building Gemini, Gemma, AI Studio and more. My views ex-Chief Llama Officer @huggingface 🇵🇪🇲🇽
merve @mervenoyann
88K Followers 5K Following (mer-veh) open-sourceress at @huggingface 🧙🏻♀️ DM me for any feedback about HF 🤗 https://t.co/MhrMkGTm7p
Jeremy Howard @jeremyphoward
314K Followers 7K Following 🇦🇺 Co-founder: @AnswerDotAI/@FastDotAI ; Prev: Professor@UQ; @kaggle founding president; founder @fastmail/@enlitic/… https://t.co/16UBFTX7mo

Soumith Chintala @soumithchintala
305K Followers 1K Following Building new things @thinkymachines. Also dabble in robotics at NYU. Cofounded @PyTorch. AI is delicious when it is accessible and open-source.
Jay Hack @mathemagic1an
70K Followers 3K Following Head of AI @clickup. Tweets about AI, computing and their impacts on society. Previously founder @codegen / ML @palantir / CS @stanford. Not a pseudonym.
Brendan Dolan-Gavitt @moyix
33K Followers 6K Following Building offsec agents: https://t.co/G9EtnC2Gl3 PGP https://t.co/3WXr0RfRkv
👩💻 Paige Bai... @DynamicWebPaige
75K Followers 2K Following ✨ AI should be about empowering humans, building understanding, and making dreams realities. 👩💻 DevX Eng. Lead @GoogleDeepMind ex-@GitHub || views = my own!

EleutherAI @AiEleuther
28K Followers 103 Following A non-profit research lab focused on interpretability, alignment, and ethics of AI. Creators of Pythia, VQGAN-CLIP, and using SAEs for interp
near @nearcyan
172K Followers 1K Following perhaps of the past, but greener pastures may still await us
Sasha Luccioni, PhD �... @SashaMTL
23K Followers 4K Following Climate & AI Lead of @HuggingFace | Member of ClimateChangeAI | @TEDTalks speaker . (She/her/Dr/🦋)
MMitchell @mmitchell_ai
82K Followers 1K Following Interdisciplinary researcher focused on shaping AI towards long-term positive goals. ML & Ethics. Similar content in the Skies (this bird has flown).
🍉 Abubakar Abid @abidlabs
14K Followers 2K Following Founder @Gradio and @FatimaFellowshp || Head of Apps @HuggingFace || Take 1 min to speak up for Gaza: https://t.co/ToigfsQCPo


Sara Hooker @sarahookr
62K Followers 11K Following Building intelligence that evolves @adaption_ai. Built @Cohere_Labs, @GoogleBrain, @GoogleDeepmind. ML Efficiency, Multimodal\lingual.
Kenley Collins @kenleycoll
8K Followers 575 Following ✨Mother of 3✨ Journalist @Bloomberg, writing for @technology. Opinions are my own. Mail: [email protected] (tips yes, pitches nono).



Shrey Singhal @imShrey1411
27 Followers 1K Following
Jakub Oblizajek @aquinas81
125 Followers 2K Following
thiagomoura @thiagomourabr
139 Followers 2K Following 📊 IA + Inteligência de Dados 💬 Bem Vindo, Gosto de falar em Inovação! 🌍 Explorando 🇳🇱🇻🇦🇮🇹🇬🇧🇵🇹🇪🇸🇩🇪🇫🇷🇧🇪🇦🇪🇺🇸🇪🇪🇫🇮🇶🇦🇨🇳
ik2ploit @ik2ploit
7 Followers 845 Following
a @fghhhvghjjgfhjj
5 Followers 1K Following

mengfong @clovermf96
0 Followers 87 Following

Louis @Louis9687221579
73 Followers 3K Following Mainline Economics | Idea page | ramblings of a schizo

Urmila Shinde @marathi_girl
97 Followers 64 Following 🚀 Turning coffee into code ☕ | Always learning and building 🌟
DigiCubeTechInc. LLC @DigiCubeTechInc
167 Followers 6K Following Magicians of creative endeavors in tech... more to come soon!

Rory @SunsupRory
46 Followers 288 Following

Helal Yehia @HelalYehia6
6 Followers 45 Following
Tom Siwik @tomhacks
48K Followers 6K Following Indie Forward Deployed Engineer ✦ epicat․com (building) ✦ https://t.co/UPfqmKCIug
Avinoam M. Oltchik @AvinoamOltchik
93 Followers 484 Following It's important to be kind when possible; it's always possible.
chunli @chunlea
420 Followers 2K Following

Buildingabot @buildingabot
150 Followers 208 Following Site Weaver – 3AI Desktop WP Plugin. Export HTML + structure. Beta soon Turning AI chats into real, navigable websites you own. https://t.co/ZZh6LZgmZj"
Jintao Huang @JintaoHuang9
152 Followers 2K Following PhD student | Decentralized AI @OhioState. Previous @Microsoft, @CertiK, @UBC, @huazhongUST
naveen @NAVEEN13104
186 Followers 446 Following Senior Robotics Product Designer | humanoid robots | Expert in robotic arms patrolling bots | R&D Innovator. https://t.co/SORXQmV1MN
Ubaid @ubaidmume
210 Followers 7K Following Students use AI for answers but don't actually learn - I'm fixing that
Praveen RS @sargaathmaka
6 Followers 391 Following Wanted to be a computer scientist. Ended up deep in product development, feature releases, maintenance etc. Now exploring AI, Robotics and the next big thing.
Sid @sid7109
1 Followers 115 Following
VU Thi Hai Yen @VUThiHaiYen9
4 Followers 28 Following
Kory Mathewson @korymath
12K Followers 6K Following @GoogleDeepMind generative AI models + agents | getting great tech into the hands of great creative people
marco barreto @marcoba19193297
60 Followers 126 Following I build applied AI for markets at Super Ezio — multi-expert orchestration, guardrails and explainable decisions.
Chaari Ahmed @Chaari_Ahmed
97 Followers 2K Following PhD in AI 🇨🇦 Ualberta - Semantic Knowledge Graphs - Reinforcement Learning - Natural Language Processing (NLP) Deep learning - Machine learning
Simon Emanuel | ses.e... @schmidsi
3K Followers 5K Following Developer Relations at @ensdomains. @nounsdao #1689
Jim Duey ن @jimduey
1K Followers 515 Following Christian, Clojure programmer, rock climber. My passion project:
Bogomil Balkansky @BogieBalkansky
6K Followers 559 Following Partner at @Sequoia working with @Wiz_io, @temporalio, @getcortexapp, @chainguard_dev, @Cyera_io, @mutinycorp, @oasissec, @pydantic, @traversal_ai.
Taishi Nakamura @taishinakamura_
3K Followers 7K Following Working on scalable and efficient LLM (MoE pretraining, RL, reasoning). PhD student at @sciencetokyo_en Intern @SakanaAILabs
alessandro @alessan26249832
27 Followers 1K Following

Rosie @xiaoruchen20001
1 Followers 23 Following
Data Value Strategy @innovimax
622 Followers 5K Following W3C Member (XSL, XQuery, XProc), ISO SC 34 Member, AFNOR Member, ANR CODEX Project
Alejandro @Alejandro898837
118 Followers 5K Following Interesado en tecnologia, medio ambiente y me encanta leer. Aficionado a la programacion e Inteligencia Artificial. Boliviano🇧🇴


FoundationModels @ramanfr
211 Followers 5K Following mostly notes to self. AI, Crypto, Computing, CPU/GPU, Longevity, Investing
Hugging Face @huggingface
701K Followers 222 Following The AI community building the future. https://t.co/TpiXQMQ9rZ
ServiceNow AI Researc... @ServiceNowRSRCH
19K Followers 1K Following Unlock work experiences of the future. Join @ServiceNowRSRCH as we advance the state-of-the-art in Enterprise AI. #ServiceNowResearch #LifeAtNow #Hiring
BigScience Research W... @BigscienceW
14K Followers 1 Following A research workshop on large language model gathering 1000+ researchers around the world Follow the training of the 176B multilingual model live @BigScienceLLMTrends for United States
You might like











